
티스토리 뷰

▶군집화(Clustering)
▷비지도 학습
비지도 학습은 기계학습의 일종으로, 데이터가 어떻게 구성되어있는지를 알아내는 문제의 범주에 속합니다.
비지도 학습은 지도학습 혹은 강화학습과는 달리 입력값에 대한 label이 주어지지 않습니다.
대표적인 예로 군집화, 이상치 탐지, 밀도 추정에 사용합니다.
▷군집화
군집화는 비지도 학습에 속하는 알고리즘으로 유사한 속성을 갖는 샘플들을 묶어 k개의 군집(cluster)으로 나누는 것입니다.
- 군집(cluster) : 비슷한 특징을 가진 샘플들의 집단
비슷한 행동을 하는 고객을 동일한 클러스터로 분류하는 고객 분류, 제시된 이미지와 비슷한 이미지를 찾아주는 검색 엔진, 차원 축소를 이용하여 분석을 위한 충분한 정보를 가질 수도 있습니다.
1) K-Means Clustering
K-Means Clustering는 군집화에서 가장 대중적으로 사용되는 알고리즘입니다.
centroid(군집 중심점)을 기준으로 가장 가까운 포인트들을 선택하는 기법을 이용합니다.
특징은 사전에 군집의 수 k를 정해주어야 알고리즘을 수행할 수가 있습니다.
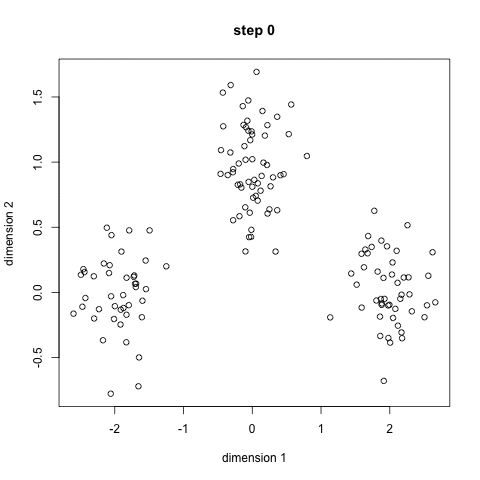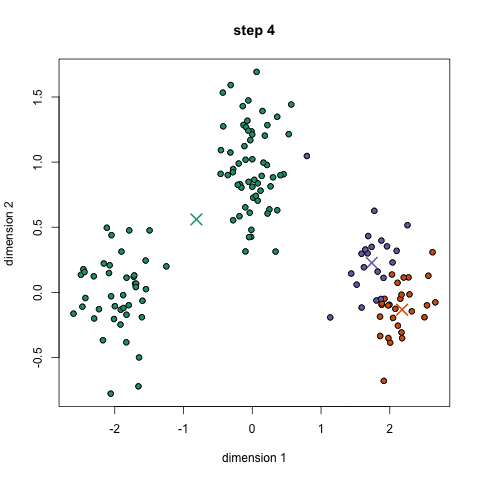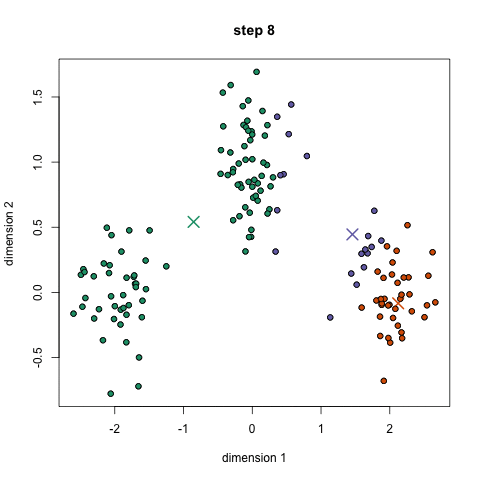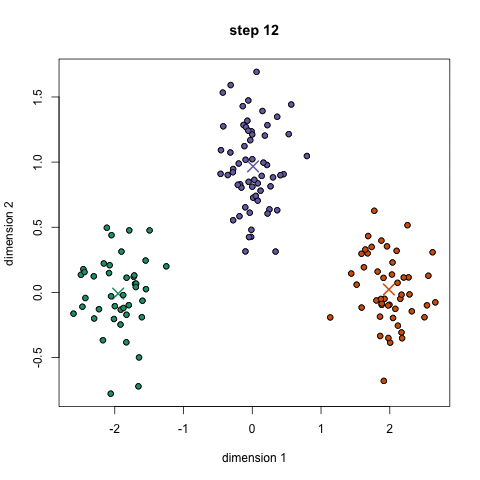
- k개의 초기 군집 중심(initial centroid)를 설정
- 모든 개체를 가장 가까운 중심에 할당하여 군집을 구성
- 할당된 개체들을 이용하여 군집 중심을 재설정(업데이트)
- 종료조건 : 모든 군집 중심들의 위치가 변하지 않고, 모든 개체의 군집 할당 결과에 변화가 없을 때(업데이트 해도 변하지 않을 때)
주의해야할 점은 초기 군집 중심에 따라 무작위로 선택되어 분석결과가 상이할 수 있습니다.
from sklearn.cluster import KMeanskmeans = KMeans(n_cluster=3) # 3개 분류로 만들어 달라는 의미
cluster_data = kmeans.fit_transform(df.loc[:, 'sepal length (cm)':'petal width (cm)'])kmeans.lables_ # 각 샘플들이 자신이 어디에 속하는지를 표시out:

sns.countplot(kmeans.lables_)out:
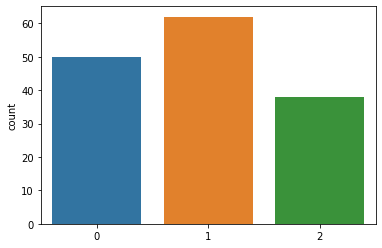
K-Means 군집화의 한계점 몇 가지를 알아보겠습니다.
① 서로 다른 크기의 군집을 잘 찾아내지 못함
② 서로 다른 밀도의 군집을 잘 찾아내지 못함
③ 지역적 패턴이 존재하는 군집을 판별하기 어려움
이러한 한계점을 극복하기 위해 나온 알고리즘을 알아보겠습니다.
2) DBSCAN(밀도기반 군집화 알고리즘)
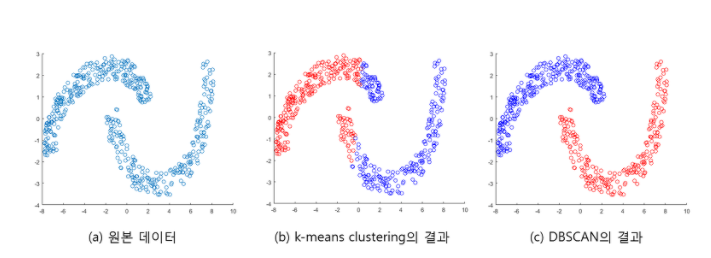
밀도기반 군집화 알고리즘은 밀도가 높은 부분을 군집화하는 방식입니다.
쉽게 말해 어느 점을 기준으로 반경 x내에 점이 n개 이상 있으면 하나의 군집으로 인식하는 방식입니다.
밀도 기반 군집화 알고리즘의 특징은 다음과 같습니다.
- 데이터 형태 무관
- 노이즈에 강건
- 낮은 알고리즘 복잡도
- 군집방식(저 밀도 지역에 의해서 고 밀도 지역 간에 군집화 됨)
DBSCAN 하이퍼 파라미터는 다음과 같습니다.
- eps : 이웃점 탐색 최대 반경
- minPts : 반경 내 이웃점의 최소한의 개수
- min_sample : 반경에 해당 숫자보다 많은 포인트가 있다면 핵심 샘플로 레이블을 할당
from sklearn.cluster import DBSCANdbscan_data = dbscan.fit_predict(df.loc[:, 'sepal length (cm)':'petal width (cm)'])
3) 군집화 평가 - 실루엣 스코어
최적의 군집 개수 k는 어떻게 찾을 수 있을까요?
바로 군집화의 품질을 정량적으로 평가해 주는 지표인 실루엣 점수라는 방법을 이용합니다.
모든 샘플에 대한 실루엣 계수의 평균을 계산하는 방법으로 실수엣 계수는 -1 ~ 1까지의 값을 가지고 1에 가까울 수록 군집이 잘 나눠진 것입니다.
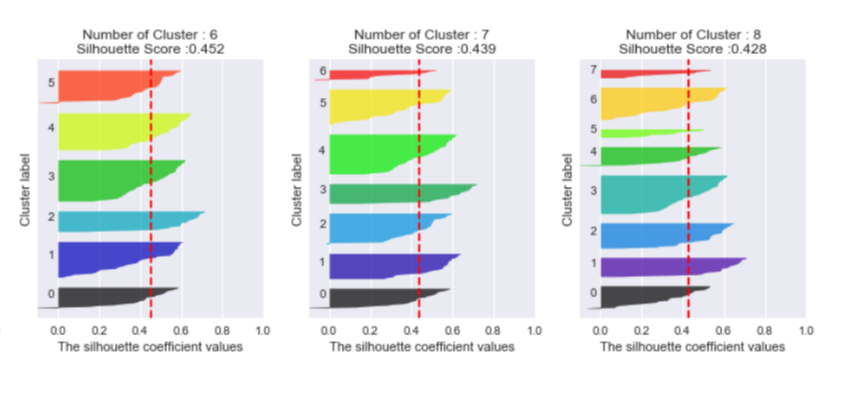
다음 API를 참고하면 도움이 될 것입니다.
Selecting the number of clusters with silhouette analysis on KMeans clustering
Silhouette analysis can be used to study the separation distance between the resulting clusters. The silhouette plot displays a measure of how close each point in one cluster is to points in the ne...
scikit-learn.org
from sklearn.metrics import silhouette_samples, silhouette_score
score = silhouette_score(data_scaled, kmeans.labels_)
score # 출력out:

이제 군집 수 k가 달라짐에 따라 실루엣 계수를 계산해 보고 시각화도 해보겠습니다.
아래 함수는 위 API에 포함되어 있습니다 :)
def plot_silhouette(X, num_cluesters):
for n_clusters in num_cluesters:
# Create a subplot with 1 row and 2 columns
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
# The 1st subplot is the silhouette plot
# The silhouette coefficient can range from -1, 1 but in this example all
# lie within [-0.1, 1]
ax1.set_xlim([-0.1, 1])
# The (n_clusters+1)*10 is for inserting blank space between silhouette
# plots of individual clusters, to demarcate them clearly.
ax1.set_ylim([0, len(X) + (n_clusters + 1) * 10])
# Initialize the clusterer with n_clusters value and a random generator
# seed of 10 for reproducibility.
clusterer = KMeans(n_clusters=n_clusters, random_state=10)
cluster_labels = clusterer.fit_predict(X)
# The silhouette_score gives the average value for all the samples.
# This gives a perspective into the density and separation of the formed
# clusters
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg)
# Compute the silhouette scores for each sample
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10
for i in range(n_clusters):
# Aggregate the silhouette scores for samples belonging to
# cluster i, and sort them
ith_cluster_silhouette_values = \
sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_clusters)
ax1.fill_betweenx(np.arange(y_lower, y_upper),
0, ith_cluster_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
# Label the silhouette plots with their cluster numbers at the middle
ax1.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
# Compute the new y_lower for next plot
y_lower = y_upper + 10 # 10 for the 0 samples
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
# The vertical line for average silhouette score of all the values
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([]) # Clear the yaxis labels / ticks
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
# 2nd Plot showing the actual clusters formed
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1], marker='.', s=30, lw=0, alpha=0.7,
c=colors, edgecolor='k')
# Labeling the clusters
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='o',
c="white", alpha=1, s=200, edgecolor='k')
for i, c in enumerate(centers):
ax2.scatter(c[0], c[1], marker='$%d$' % i, alpha=1,
s=50, edgecolor='k')
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()즉 k=2, 3, 4, 5 일 때를 보겠다는 말입니다.
plot_silhouette(data_scaled, [2, 3, 4, 5])out:
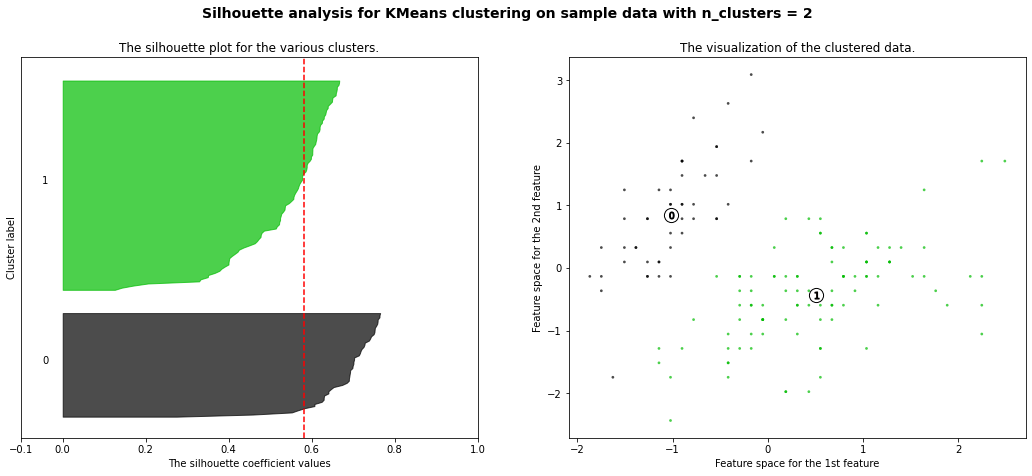


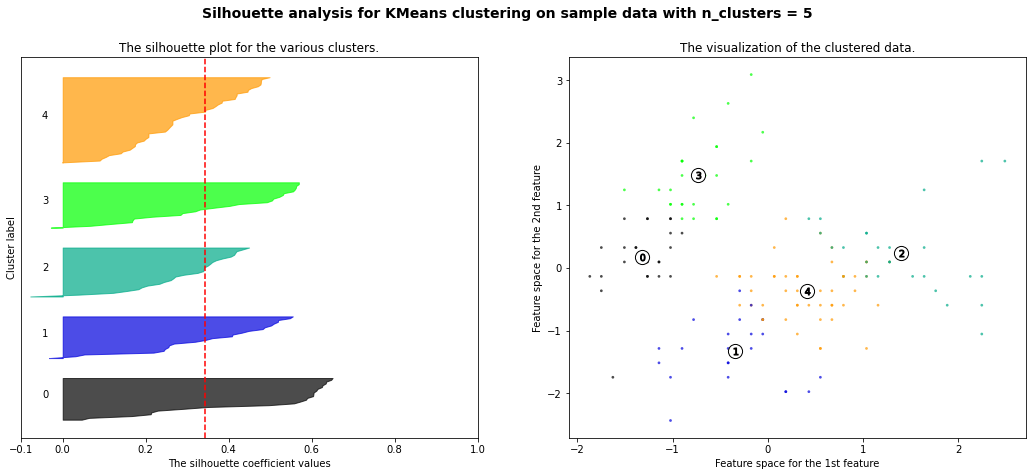
실루엣 계수 즉 얼마나 군집화가 잘 되었는지를 점수를 매긴 숫자를 보면 k=2일 때가 가장 높으므로 군집의 수를 2로 결정하면 되겠습니다.
참고로 빨간색 점선은 평균 실루엣 게수를 의미합니다.

여기까지 군집화에 대해 알아보았습니다 :)
'빅데이터 인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝] ⑮ 차원 축소(Dimensionality Reduction) (0) | 2022.08.30 |
|---|---|
| [머신러닝] ⑪ 하이퍼 파라미터 튜닝을 쉽게 (0) | 2022.08.23 |
| [머신러닝] ⑩ 교차 검증(Cross Validation) (0) | 2022.08.23 |
| [머신러닝] ⑩ random_state에 대해서 (0) | 2022.08.22 |
| [머신러닝] ⑨ 앙상블(Ensemble) 모델 (0) | 2022.08.21 |
- Total
- Today
- Yesterday
- Python
- 스타일 컴포넌트 styled-components
- jest
- react-query
- 자바스크립트 기초
- styled-components
- 리액트 훅
- 머신러닝
- HTML
- rtl
- 데이터분석
- frontend
- 프로젝트 회고
- 디프만
- 프론트엔드
- 타입스크립트
- CSS
- 파이썬
- JSP
- 프론트엔드 기초
- 인프런
- 리액트
- 프론트엔드 공부
- 자바스크립트
- react
- 딥러닝
- next.js
- TypeScript
- testing
- 자바
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |