
티스토리 뷰

▶하이퍼파라미터 튜닝을 쉽게
하이퍼파라미터 튜닝 시 경우의 수가 너무 많습니다.
이를 자동화할 필요가 있으며, 사이킷런 패키지에서는 자주 사용되는 하이퍼파라미터 튜닝을 돕는 클래스가 존재합니다.
대표적인 방법 두 가지는 다음과 같습니다.
- RandomizedSearchCV
- GridSearchCV
또한 적용하는 방법은 다음과 같습니다.
- 사용할 Search 방법을 선택
- hyperparameter 도메인을 설정(max_depth, n_estimators..등)
- 학습을 시킨 후 기다림
- 도출된 결과 값을 모델에 적용하고 성능을 비교
1) RandomizedSearchCV
RandomizedSearchCV 방법은 모든 매개변수 값이 시도되는 것이 아니라 지정된 분포에서 고정된 수의 매개변수 설정이 샘플링 됩니다.
다시 말해, 내가 지정한 하이퍼파라미터 보기들과 내가 지정한 반복수를 통해 최적의 하이퍼파라미터를 탐색하는 것입니다.
우선 적용해 보고 싶은 하이퍼파라미터 값들을 딕셔너리에 담아주겠습니다.
params = {
'n_estimaters' : [200, 500, 1000, 2000],
'learning_rate' : [0.1, 0.05, 0.01],
'max_depth' : [6, 7, 8],
'colsample_bytree' : [0.8, 0.9, 1.0], # 샘플 사용 비율. (max_features와 비슷한 개념). 과대적합 방지용. default=1.0
'subsample' : [0.8, 0.9, 1.0]
}이제 학습을 진행해 보겠습니다.
from sklearn.model_selection import RandomizedSearchCVRandomizedSearchCV를 LightGBM에 적용해 보도록 하겠습니다.
주요 하이퍼파라미터는 다음과 같습니다.
- estimator : 모델 객체 지정
- param_distributions : 하이퍼파리미터 목록을 dictionary 로 전달
- n_iter : 파라미터 검색 횟수
- scoring : 평가 지표
- cv : 교차검증 시 fold 개수
- n_jobs : 사용할 CPU 코어 개수(1: 기본값, -1: 모든 코어 다 사용)
# n_iter : 총 몇회의 시도를 진행할 것인지 정의(횟수가 늘어나면 좋은 파라미터를 찾을 확률이 높지만 그만큼 시간이 오래 걸림)
# cv: 검증을 위한 분할 검증 횟수
# scoring : 뭘 기준으로 점수를 부여할지
rdm = RandomizedSearchCV(LGBMRegressor(), params, random_state=10, n_iter=25, cv=3, scoring='neg_mean_squared_error')rdm.fit(x_train, y_train)학습을 시켰으니 결과를 조회해 보아야겠죠?
결과 조회 변수는 다음과 같습니다.
- cv_results_ : 파라미터 조합별 결과 조회
- best_params_ : 가장 좋은 성능을 낸 parameter 조합 조회
- best_estimator_ : 가장 좋은 성능을 낸 모델 반환
rdm.best_params_out:
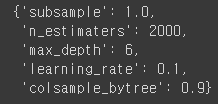
위 처럼 가장 좋은 파라미터 조합을 알려주게 됩니다.
알려준 대로 모델을 학습 시키면 되겠습니다.
lgbm_best = LGBMRegressor(subsample=1.0, n_estimators=2000, max_depth=6, learning_rate=0.1, colsample_bytree=0.9)
lgbm_best_pred = lgbm.fit(x_train, y_train).predict(x_test)
mse_eval('RandomSearch LGBM', lgbm_best_pred, y_test)out:
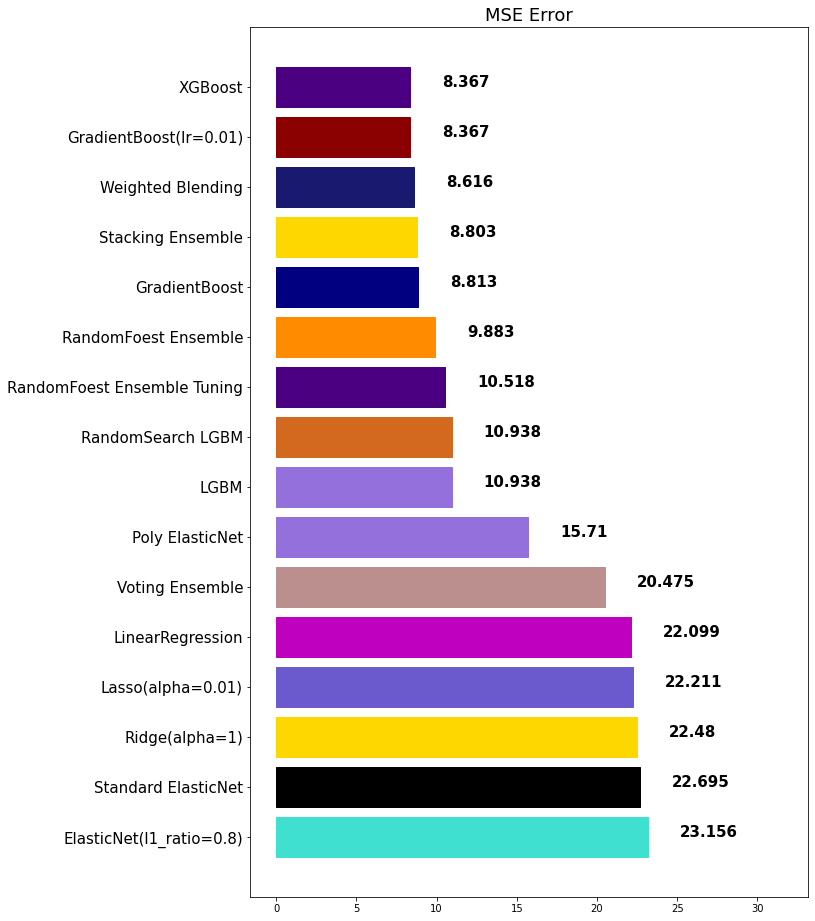
2) GridSearchCV
GridSearchCV는 RandomizedSearchCV와 달리 모든 매개변수 값에 대하여 완전 탐색을 시도합니다.
그러므로 최적화할 파라미터가 많다면 시간이 매우 오래 걸리게 됩니다.
RandomizedSearchCV와 동일하게 하이퍼파라미터들 딕셔너리로 만들어줘야하는 점은 동일합니다.
params = {
'n_estimaters' : [500, 1000],
'learning_rate' : [0.1, 0.05, 0.01],
'max_depth' : [7, 8],
'colsample_bytree' : [0.8, 0.9],
'subsample' : [0.8, 0.9]
}from sklearn.model_selection import GridSearchCVgrid_search = GridSearchCV(LGBMRegressor(), params, cv=3, n_jobs=-1, scoring='neg_mean_squared_error')
grid_search.fit(x_train, y_train)grid_search.best_params_out:

lgbm_best = LGBMRegressor(n_estimators=500, subsample=0.8, learning_rate=0.1, max_depth=7)
lgbm_best_pred = lgbm_best.fit(x_train, y_train).predict(x_test)
mse_eval('GridSearch LGBM', lgbm_best_pred, y_test)out:


여기까지 하이퍼파라미터 튜닝을 쉽게 하는 방법에 대해 알아보았습니다 :)
728x90
LIST
'빅데이터 인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝] ⑮ 차원 축소(Dimensionality Reduction) (0) | 2022.08.30 |
|---|---|
| [머신러닝] ⑫ 군집화(Clustering) in 비지도학습 (0) | 2022.08.24 |
| [머신러닝] ⑩ 교차 검증(Cross Validation) (0) | 2022.08.23 |
| [머신러닝] ⑩ random_state에 대해서 (0) | 2022.08.22 |
| [머신러닝] ⑨ 앙상블(Ensemble) 모델 (0) | 2022.08.21 |
250x250
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 리액트 훅
- 프로젝트 회고
- 데이터분석
- 프론트엔드 공부
- 자바스크립트 기초
- 프론트엔드
- 스타일 컴포넌트 styled-components
- jest
- CSS
- TypeScript
- styled-components
- HTML
- testing
- Python
- 리액트
- 프론트엔드 기초
- 파이썬
- rtl
- JSP
- next.js
- 자바스크립트
- 머신러닝
- 디프만
- 타입스크립트
- 자바
- 딥러닝
- react
- frontend
- 인프런
- react-query
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함