
티스토리 뷰

▶교차 검증(Cross Validation)
보통은 train set으로 모델을 훈련, test set으로 모델을 검증합니다.
하지만 이 방법은 고정된 test set을 통해 모델의 성능을 검증하고 수정하는 과정을 반복하게 되면서 결국 해당 test set에만 잘 동작하는 모델이 되게 됩니다.
다시 말해 해당 test set에 과적합(overfitting)하게 되므로, 또 다른 새로운 데이터에 대해서는 예측 성능이 좋지 않게 되는 것입니다.
이를 해결하고자 하는 것이 바로 교차 검증(cross validation)입니다.
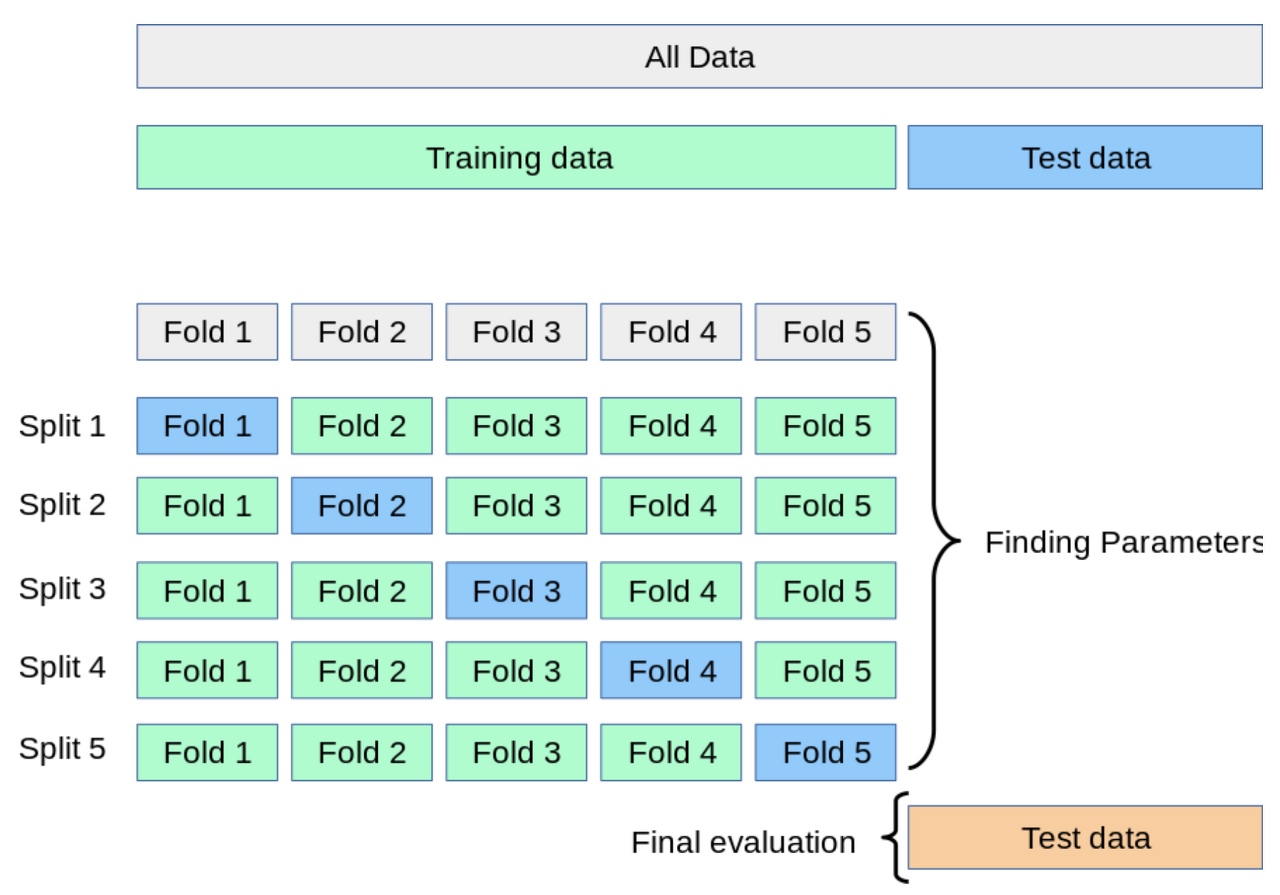
교차검증의 장점은 모든 데이터셋을 훈련에 활용할 수 있어 정확도를 향상시킬 수 있고 데이터 부족으로 인한 과소적합(underfitting)을 방지할 수 있습니다.
또한 모든 데이터셋을 평가에도 활용할 수 있어 좀 더 일반화된 모델을 만들 수 있게 됩니다.
단점이라고 볼 수 있는 점은 모든 데이터셋에 대해 훈련과 평가를 해야 하기 때문에 itertation 횟수가 많게 되고 이는 훈련과 평가 시간이 오래 걸리는 이유로 작용하게 됩니다.
가장 일반적으로 사용되는 교차 검증 방법인 K-Fold에 대해 알아봅시다.
K-Fold 교차 검증은 모든 데이터가 최소 한 번은 테스트셋으로 쓰이도록 합니다.
이때 하이퍼파라미터로 k를 설정해주어 몇 번의 훈련/평가를 할지 정해줄 수 있습니다.
from sklearn.model_selection import KFoldn_split = 5
# random_state 필수
kfold = KFold(n_splits=n_split, random_state=42, shuffle=True)X = np.array(df.drop('MEDV', 1))
Y = np.array(df['MEDV'])저는 LightGBM에 K-Fold 교차 검증을 적용해보겠습니다.
lgbm_fold = LGBMRegressor(random_state=42)위에서 kfold 객체를 만들 때 사용한 random_state와 같은 number를 입력해줍니다.
이제 fold 마다의 성능과 평균 성능을 출력하는 반복문을 작성해줍시다.
i = 1
total_error = 0
for train_index, test_index in kfold.split(X):
x_train_fold, x_test_fold = X[train_index], X[test_index]
y_train_fold, y_test_fold = Y[train_index], Y[test_index]
lgbm_pred_fold = lgbm_fold.fit(x_train_fold, y_train_fold).predict(x_test_fold)
error = mean_squared_error(lgbm_pred_fold, y_test_fold)
print('Fold = {}, prediction score = {:.2f}'.format(i, error))
total_error += error
i += 1
print('---'*10)
print('Average Error: %s' % (total_error / n_splits))

여기까지 교차 검증에 대해 알아보았습니다 :)
'빅데이터 인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝] ⑫ 군집화(Clustering) in 비지도학습 (0) | 2022.08.24 |
|---|---|
| [머신러닝] ⑪ 하이퍼 파라미터 튜닝을 쉽게 (0) | 2022.08.23 |
| [머신러닝] ⑩ random_state에 대해서 (0) | 2022.08.22 |
| [머신러닝] ⑨ 앙상블(Ensemble) 모델 (0) | 2022.08.21 |
| [머신러닝] ⑧ 오차 행렬(Confusion matrix) in 분류 (0) | 2022.08.19 |
- Total
- Today
- Yesterday
- styled-components
- 디프만
- Python
- 프론트엔드 공부
- react
- react-query
- 프론트엔드
- 자바스크립트 기초
- 딥러닝
- 리액트 훅
- 인프런
- testing
- rtl
- 프로젝트 회고
- 자바
- 스타일 컴포넌트 styled-components
- 머신러닝
- 타입스크립트
- 프론트엔드 기초
- jest
- CSS
- next.js
- JSP
- 데이터분석
- 파이썬
- 리액트
- 자바스크립트
- HTML
- TypeScript
- frontend
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |