
티스토리 뷰

▶앙상블(Ensemble) 모델
머신러닝 앙상블이란 여러 개의 머신러닝 모델을 이용해 최적의 답을 찾아내는 기법입니다.
앙상블 기법의 종류는 다음과 같습니다.
- 보팅(Voting) : 투표를 통해 결과를 도출
- 배깅(Bagging) : 샘플 중복 생성을 통해 결과를 도출
- 부스팅(Boosting) : 이전 오차를 보완하면서 가중치를 부여
- 스태킹(Stacking) : 여러 모델을 기반으로 예측된 결과를 통해 meta 모델이 다시 한번 에측
이전에 회귀(Regression) 모델 글에서 사용한 예측 성능 시각화 함수(mse_eval)를 이용해서 모델 성능을 비교해보겠습니다.
함수에 대한 자세한 설명은 다음 링크를 참고해주세요 :)
[머신러닝] ⑥ 회귀(Regression) 분석 A to Z
▶회귀분석(Regression) 머신러닝은 데이터를 읽어 학습하고 예측값을 찾는 것입니다. 그중에서도 회귀분석은 독립변수(x)와 종속변수(y)를 예측하는 것을 의미합니다. 이번 글에서는 사이킷런에서
doeunn.tistory.com
from sklearn.metrics import mean_absolute_error, mean_squared_errorimport matplotlib.pyplot as plt
import seaborn as sns
my_predictions = {}
colors = ['r', 'c', 'm', 'y', 'k', 'khaki', 'teal', 'orchid', 'sandybrown',
'greenyellow', 'dodgerblue', 'deepskyblue', 'rosybrown', 'firebrick',
'deeppink', 'crimson', 'salmon', 'darkred', 'olivedrab', 'olive',
'forestgreen', 'royalblue', 'indigo', 'navy', 'mediumpurple', 'chocolate',
'gold', 'darkorange', 'seagreen', 'turquoise', 'steelblue', 'slategray',
'peru', 'midnightblue', 'slateblue', 'dimgray', 'cadetblue', 'tomato']
def plot_predictions(name_, pred, actual):
df = pd.DataFrame({'prediction': pred, 'actual': y_test})
df = df.sort_values(by='actual').reset_index(drop=True)
plt.figure(figsize=(12, 9))
plt.scatter(df.index, df['prediction'], marker='x', color='r')
plt.scatter(df.index, df['actual'], alpha=0.7, marker='o', color='black')
plt.title(name_, fontsize=15)
plt.legend(['prediction', 'actual'], fontsize=12)
plt.show()
def mse_eval(name_, pred, actual):
global my_prediction
global colors
plot_predictions(name_, pred, actual)
mse = mean_squared_error(pred, actual)
my_predictions[name_] = mse
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=True) # x의 두번째 자리 숫자 가져와서 내림차순
df = pd.DataFrame(y_value, columns=['model', 'mse'])
print(df)
min_ = df['mse'].min() - 10 # 그래프를 그릴 때 보기 좋으라고 상한과 하한을 주기 위해서
max_ = df['mse'].max() + 10
length = len(df)
plt.figure(figsize=(10, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=15)
bars = ax.barh(np.arange(len(df)), df['mse'])
for i, v in enumerate(df['mse']): # mse 데이터에 index값과 value 값이 있는데 각각 i와 v로 for문
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=15, fontweight='bold')
plt.title('MSE Error', fontsize=18)
plt.xlim(min_, max_)
plt.show()우선 앙상블 모델이 아닌 단일 모델 몇 가지를 불러오겠습니다.
불러온 결과는 다음과 같습니다.
out:
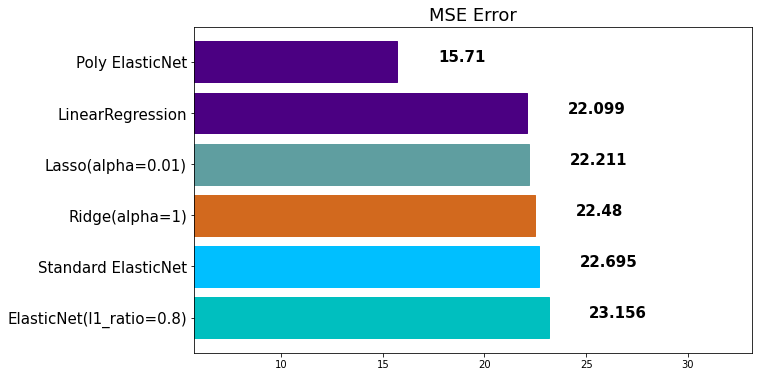
1) 보팅(Voting) - 회귀(Regression)

Voting은 투표를 통해 결정하는 방식입니다.
Bagging과 투표 방식이라는 점에서 유사하지만, 아래와 같은 큰 차이점이 있습니다.
- Voting은 다른 알고리즘을 모델로 조합해서 사용
- Bagging은 같은 알고리즘 내에서 다른 sample로 나눠 조합해 사용
from sklearn.ensemble import VotingRegressor이제 Voting할 때 사용할 서로 다른 알고리즘들을 선택해줄 겁니다.
반드시 tuple 형태로 입력해야 한다는 점을 기억합시다.
참고로, 아래 코드에 입력한 모델들은 위에서 먼저 학습시킨 단일 모델들입니다.
single_models = [
('linear-reg', linear_reg),
('ridge', ridge),
('lasso', lasso),
('elasticnet_pipeline', elasticnet_pipeline),
('poly_pipeline', poly_pipeline)
]voting_regressor = VotingRegressor(single_models, n_jobs=-1) # n_jobs=-1 : CPU 최대로 사용voting_pred = voting_regressor.fit(x_train, y_train).predict(x_test)성능을 시각화 해봅시다.
mse_eval('Voting Ensemble', voting_pred, y_test)out:

2) 보팅(Voting) - 분류(Classification)
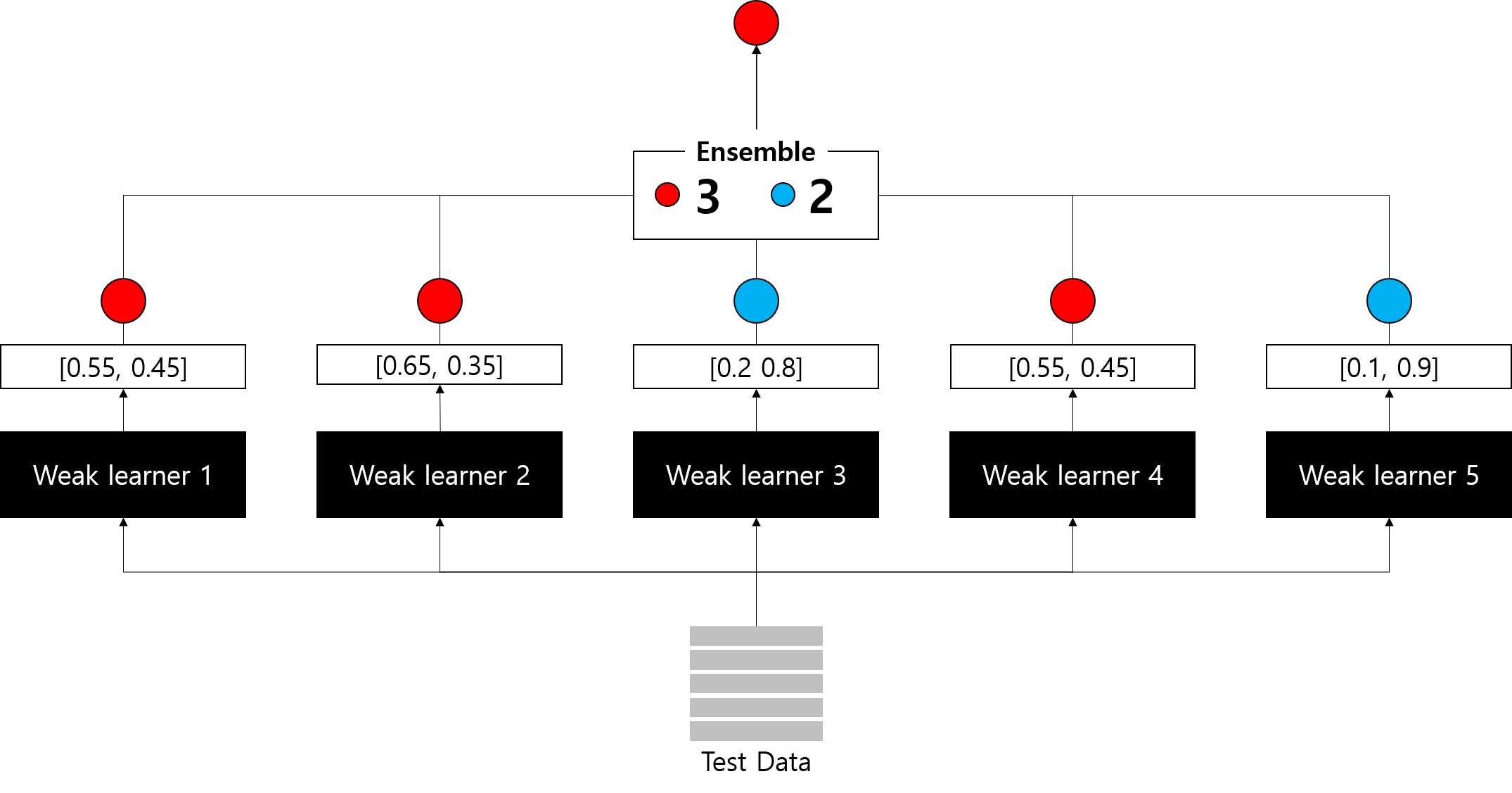
분류기 모델을 만들 때, Voting 앙상블은 중요한 파라미터가 존재합니다.
바로 voting = {'hard', 'soft'} 입니다.
① hard : class 0, 1로 분류 에측을 하는 이진 분류일 때 결과 값에 대한 다수 class를 차용
- 예) 분류를 예측한 값이 1, 0, 0, 1, 1 이었다면 1이 3표, 0이 2표를 받았으므로 1이 최종값으로 예측하게 됨
② soft : 각각의 확률의 평균값을 계산한 다음에 가장 높은 확률 값으로 확정
- 예) class 0이 나올 확률이 [0.4, 0.9, 0.9, 0.4, 0.4], class 1이 나올 확률이 [0/6, 0.1, 0.1, 0.6, 0.6]
- class 0이 나올 최종 확률 : (0.4 + 0.9 + 0.9 + 0.4 + 0.4) / 5 = 0.6
- class 1이 나올 최종 확률 : (0.6 + 0.1 + 0.1 + 0.6 + 0.6) / 5 = 0.4
- 따라서 최종적으로 class 0로 확정
from sklearn.ensemble import VotingClassifiermodels = [
('Logi', LogisticRegression()),
('ridge', RidgeClassifier())
]vc = VotingClassifier(models, voting='hard')
3) 배깅(Bagging)
배깅은 Bootstrap Aggregating의 줄임말로 Bootstrap은 여러 개의 데이터셋의 중첩을 허용하게 하여 샘플링하여 분할하는 방식을 말합니다.
다시말해 배깅은 샘플을 여러 번 뽑아(Bootstrap) 각 모델을 학습시켜 결과물을 집계(Aggregation)하는 방법입니다.

학습 과정은 데이터로부터 부트스트랩을 합니다.
그 후 중복을 허용한 부트스트랩한 데이터로 모델을 각각 학습시킵니다.
그리고 학습된 모델의 결과를 집계하여 최종 결과 값을 구합니다.
이때 보팅과의 차이점이 나오죠?
보팅 → 데이터 나눔 X, 학습 모델 나눔 O(여러 학습 방식을 사용)
부스팅 → 데이터 나눔 O, 학습 모델 나눔 X(같은 학습 방식을 사용)
4) 랜덤포레스트(RandomForest) - 배깅 기법
랜덤포레스트는 의사결정나무(Decision Tree) 기반 배깅 앙상블입니다.
Decision tree는 과대적합될 가능성이 높습니다.
이 과대적합을 가지치기(Pruning)를 통해 트리의 최대 높이를 설정해서 과대적합을 해결하고자 하지만 충분히 해결할 수는 없습니다.
그러므로 좀 더 일반화 성능이 높은 트리를 만드는 방법이 필요합니다.

이때 Random Forest는 여러 개의 decision tree를 형성하고 새로운 데이터 포인트를 각 트리에 동시에 통과시키며, 각 트리가 분류한 결과에서 투표를 실시하여 가장 많이 득표한 최종 분류 결과로 선택합니다.

from sklearn.ensemble import RandomForestRegressor, RandomForestClassifierrfr = RandomForestRegressor()
rfr_pred = rfr.fit(x_train, y_train).predict(x_test)mse_eval('RandomFoest Ensemble', rfr_pred, y_test)out:
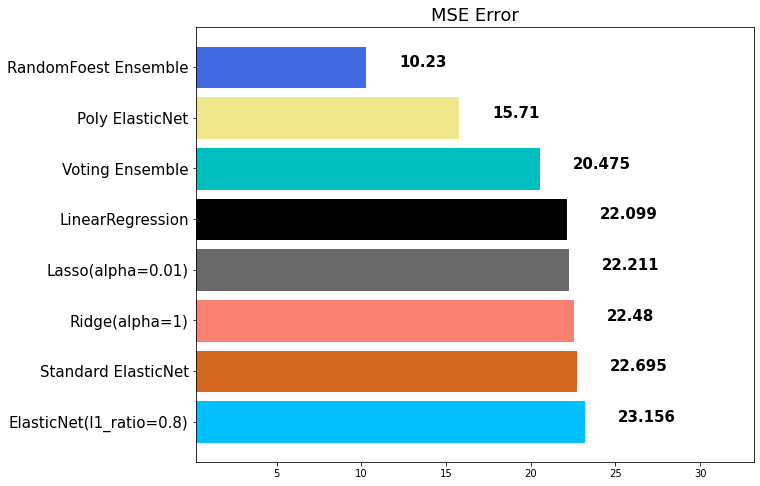
랜덤 포레스트도 전혀 과대적합이 없는 것은 아닙니다.
과대적합을 방지하기 위해 랜덤포레스트도 하이퍼파라미터 튜닝을 해줄 수 있습니다.
참고로 하이퍼파라미터를 어떻게 하느냐에 따라 성능이 좋아질 수도 오히려 나빠질 수도 있습니다.
- max_depth : 깊어질 수 있는 최대 깊이, 과대적합 방지용
- n_estimators : 앙상블하는 트리의 개수
- max_features : 최대로 사용할 feature의 개수, 과대적합 방지용. 퍼센트로도 입력 가능
- min_sample_split : 트리가 분할할 때 최소 샘플의 개수, default=2. 과대적합 방지용
rfr = RandomForestRegressor(
random_state=10,
n_estimators=1000,
max_depth=7, max_features=0.9)rfr_pred = rfr.fit(x_train, y_train).predict(x_test)mse_eval('RandomFoest Ensemble Tuning', rfr_pred, y_test)out:
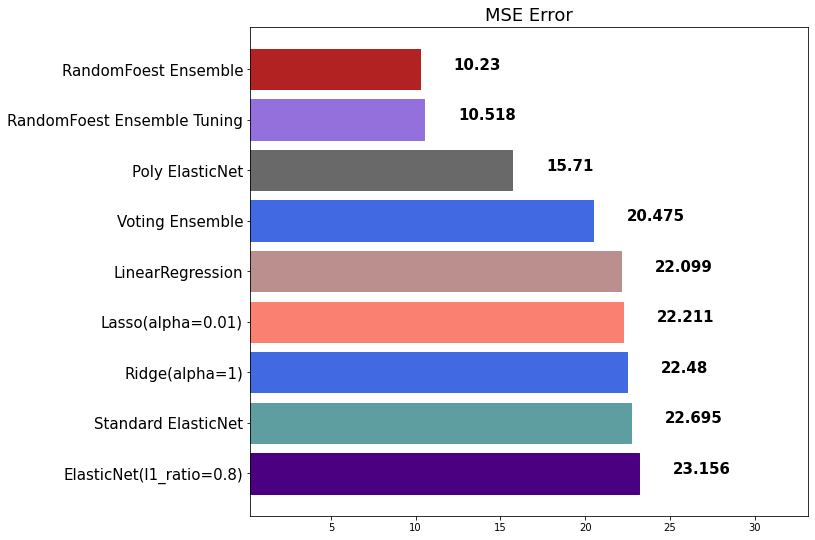
5) 부스팅(Boosting)
부스팅은 weak learner를 순차적으로 학습을 하되, 이전 학습에 대하여 잘못 예측된 데이터에 가중치를 부여해 오차를 보완해 나가는 방식입니다.
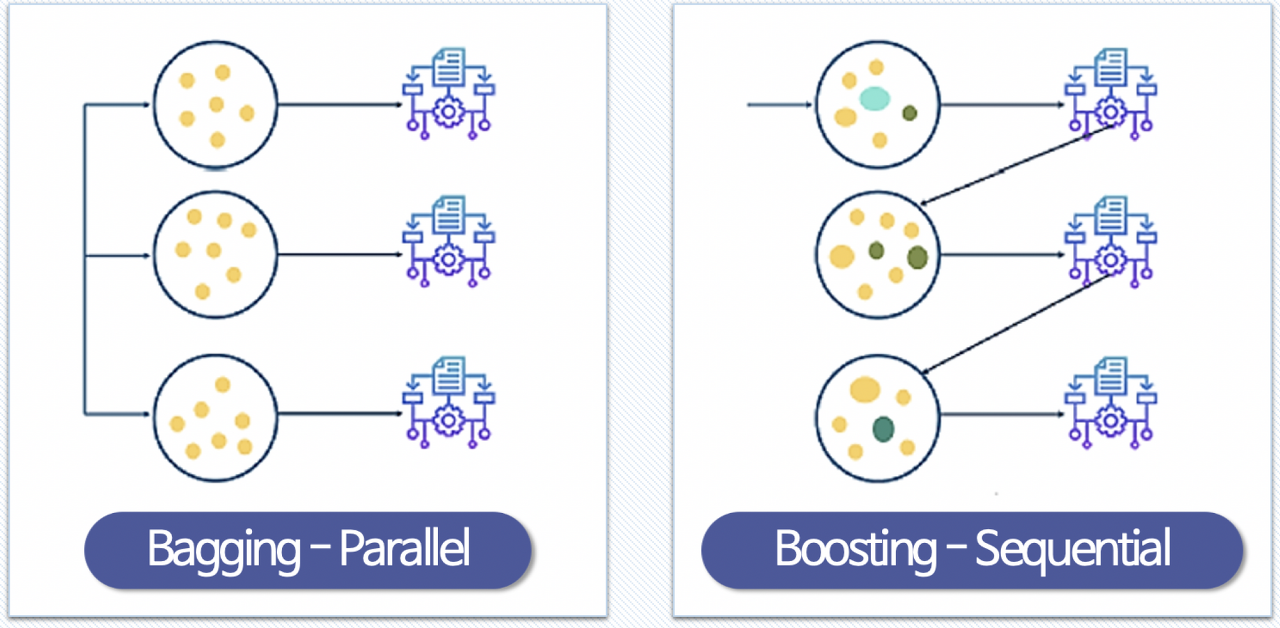
장점은 성능이 매우 우수합니다.
다만, 부스팅 알고리즘의 특성 상 계속해서 약점(오분류, 잔차)을 보완하려고 하기 대문에 잘못된 레이블링이나 아웃라이어에 필요 이상으로 민감할 수가 있습니다.
그렇기 때문에 다른 앙상블 대비 학습 시간이 오래 걸린다는 단점이 있습니다.
6) GradientBoost(GBM) - 부스팅 기법 ①

Gradient Boost는 gradient decent algorithm을 이용해서 error를 최소화하는 기법입니다.
학습 방식은 우선 모델 A를 통해 y를 예측하고 남은 잔차(residual)을 개선하는 방향으로 다음 모델 B를 만들고 계속 반복해 나갑니다.
따라서 성능이 우수합니다.
다만, 최대 단점은 학습 시간이 정말 정말 느리다는 것입니다.
from sklearn.ensemble import GradientBoostingRegressor, GradientBoostingClassifiergbr = GradientBoostingRegressor(random_state=10)
gbr_pred = gbr.fit(x_train, y_train).predict(x_test)mse_eval('GradientBoost', gbr_pred, y_test)out:

GBM도 하이퍼파라미터 튜닝을 통해 좀 더 좋은 모델을 만들 수 있습니다.
- learning_rate : 학습률. 너무 큰 학습률은 성능을 떨어뜨리고, 너무 작은 학습률은 학습이 느림. 적절한 값을 찾아야 함. n_estimators와 같이 튜닝. default=0.1
- n_estimators : 부스팅 스테이즈 수. (랜덤포레스트 트리의 개수와 비슷한 개념). default-100
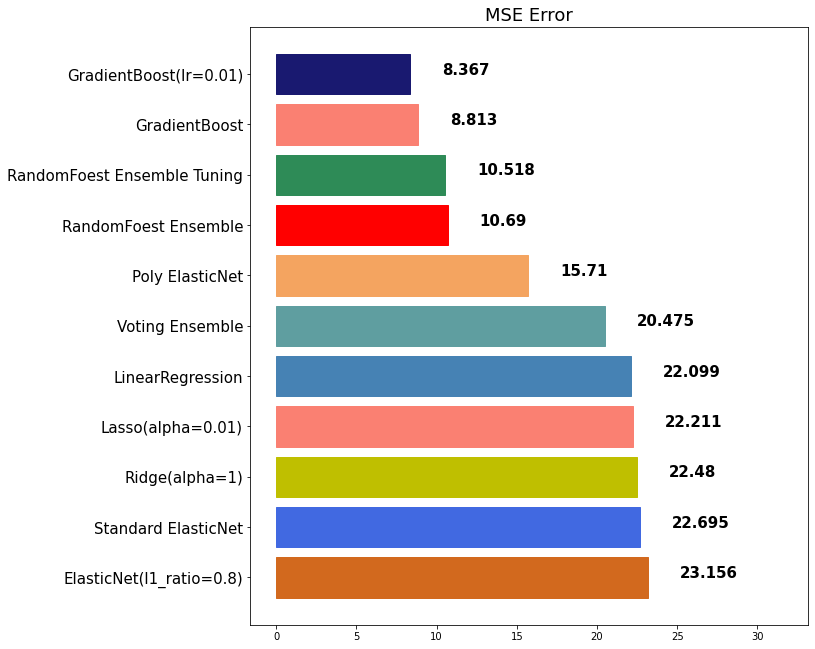
gbr = GradientBoostingRegressor(random_state=10, learning_rate=0.01, n_estimators=1000)gbr_pred = gbr.fit(x_train, y_train).predict(x_test)mse_eval('GradientBoost(lr=0.01)', gbr_pred, y_test)out:
7) XGBoost - 부스팅 기법 ②
XGBoost는 eXtreme Gradient Boosting의 약자로 Boosting 기법을 이용한 알고리즘입니다.
GBM의 느린 학습 속도를 개선하고자 XGBoost는 병렬 처리로 학습을 진행하여 GBM 보다 분류 속도가 빠릅니다.
참고로 scikit-learn 패키지가 아닙니다.
from xgboost import XGBClassifier, XGBRegressorxgb = XGBRegressor(random_state=10)
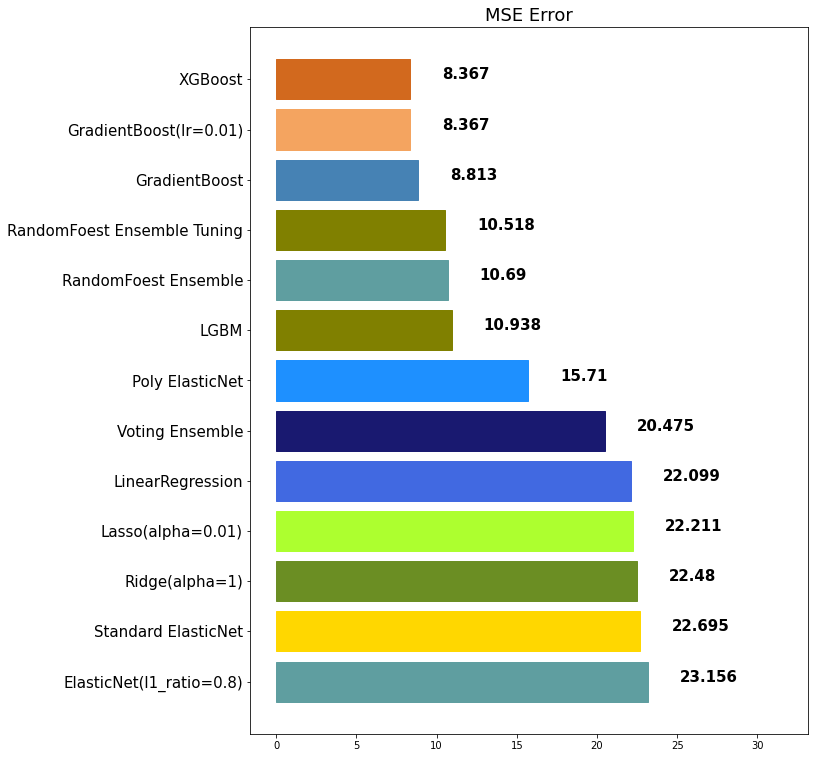
xgb_pred = xgb.fit(x_train, y_train).predict(x_test)mse_eval('XGBoost', xgb_pred, y_test)out:

8) LightGBM - 부스팅 기법 ③
LightGBM은 기존 Boosting 기법 모델들과 tree 확장 방식이 조금 다릅니다.

기존 Boosting 기법 알고리즘들은 level-wise하게 레벨의 노드를 모두 확장하면 다음 레벨로 넘어가는 방식입니다.
그렇기 때문에 해당 노드가 좋고 나쁠 거 상관 없이 확장을 하고 다음 노드로 넘어가야 하기 때문에 속도가 느립니다.

하지만 LightGBM은 좋은 노드에 대해서는 먼저 수직으로 노드를 확장해 나아가기 때문에 속도가 훨씬 더 빠릅니다.
더불어 성능 부분에서도 우수합니다.
from sklearn import LGBMClassifier, LGBMRegressorlgbm = LGBMRegressor()
lgbm_pred = lgbm.fit(x_train, y_train).predict(x_test)mse_eval('LGBM', lgbm_pred, y_test)out:
9) 스태킹(Stacking)
스태킹은 여러 가지 모델들의 예측값을 최종 모델의 학습 데이터로 사용하는 예측 방법입니다.
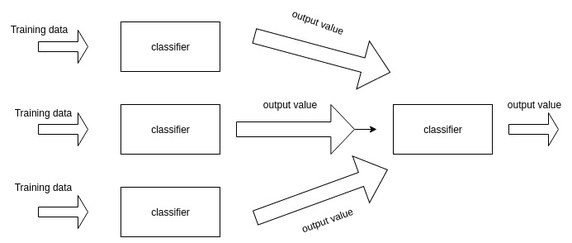
주의할 점은 스태킹은 데이터셋이 적은 경우 과대적합을 유발할 수 있습니다.
from sklearn.ensemble import StackingRegressorstack_models = [
('elasticnet', poly_pipeline),
('randomforest', rfr),
('gbr', gbr),
('lgbm', lgbm)
]# xgb를 마지막으로 한번더 사용하겠습니다.
stack_reg = StackingRegressor(stack_models, final_estimator=xgb, n_jobs=-1)stack_pred = stack_reg.fit(x_train, y_train).predict(x_test)mse_eval('Stacking Ensemble', stack_pred, y_test)out:
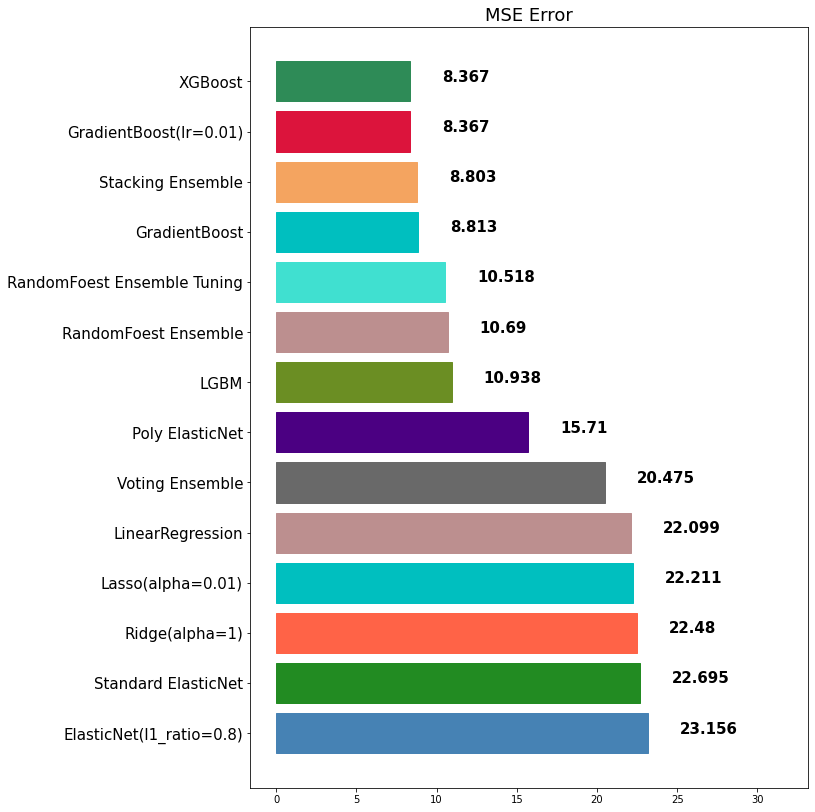
10) Weighted Blending
Weighted Blending은 각 모델의 예측값에 대하여 가중치(weight)를 곱하여 최종 output을 계산하는 기법입니다.
다시 말해 각각 학습시킨 모델에 대한 가중치를 조절하여 최종 모델을 만들어내는 방식입니다.
참고로, 가중치의 합은 1.0이 되도록 해야 합니다.
# 예측값들을 넣습니다.
final_outputs = {
'elasticnet': poly_pred,
'randomforest': rfr_pred,
'gbr': gbr_pred,
'xgb': xgb_pred,
'lgbm': lgbm_pred,
'stacking': stack_pred
}
해당 데이터 마다 좋은 성능을 보이는 알고리즘들은 매번 다를 것입니다.
그 알고리즘을 파악해서 좋은 성능을 보이는 알고리즘 순으로 큰 가중치를 부여해서 혼합하는 것이 weighted blending의 포인트입니다.
final_prediction=\
final_outputs['elasticnet'] * 0.1\
+ final_outputs['randomforest'] * 0.1\
+ final_outputs['gbr'] * 0.2\
+ final_outputs['xgb'] * 0.25\
+ final_outputs['lgbm'] * 0.15\
+ final_outputs['stacking'] * 0.2mse_eval('Weighted Blending', final_prediction, y_test)out:


여기까지 머신러닝 앙상블 모델에 대해 알아보았습니다 :)
앙상블 기법은 대체적으로 단일 모델 대비 성능이 좋았습니다.
앙상블을 앙상블하는 기법인 Stacking과 Weighted Blending도 알아보았습니다.
하지만 앙상블을 단일 모델을 합쳐서 학습시키다보니 단일 모델에 비해 학습시간이 더 오래걸린다는 특징도 있었습니다.
또한 하이퍼파라미터에 영향을 많이 받는 알고리즘은
여러 경우를 적용해 보아 좋은 성능을 찾는 데까지는 오랜 시간이 소요되겠습니다.
'빅데이터 인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝] ⑩ 교차 검증(Cross Validation) (0) | 2022.08.23 |
|---|---|
| [머신러닝] ⑩ random_state에 대해서 (0) | 2022.08.22 |
| [머신러닝] ⑧ 오차 행렬(Confusion matrix) in 분류 (0) | 2022.08.19 |
| [머신러닝] ⑦ 분류(Classification) 모델 (0) | 2022.08.19 |
| [머신러닝] ⑥ 회귀(Regression) 분석 A to Z (0) | 2022.08.12 |
- Total
- Today
- Yesterday
- CSS
- react-query
- 데이터분석
- 디프만
- 스타일 컴포넌트 styled-components
- HTML
- frontend
- react
- 타입스크립트
- 자바스크립트
- 리액트 훅
- Python
- TypeScript
- 프론트엔드
- 파이썬
- testing
- 프론트엔드 공부
- JSP
- 리액트
- 딥러닝
- rtl
- jest
- 머신러닝
- next.js
- 프로젝트 회고
- 프론트엔드 기초
- 인프런
- styled-components
- 자바
- 자바스크립트 기초
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |