
티스토리 뷰

▶회귀분석(Regression)
머신러닝은 데이터를 읽어 학습하고 예측값을 찾는 것입니다.
그중에서도 회귀분석은 독립변수(x)와 종속변수(y)를 예측하는 것을 의미합니다.
이번 글에서는 사이킷런에서 제공하고 있는 데이터셋인 '보스턴의 집값 데이터' load_boston을 이용해서 공부할 예정입니다.
import pandas as pd
import numpy as np
np.set_printoptions(suppress-True) # 19e-2 이런식으로 e를 사용하지 않고 그냥 펼쳐서 보여줌
▷데이터 확인 및 불러오기
from sklearn.datasets import load_boston
data = load_boston()
data 객체를 만들고서 print 해보면 우리가 원하는 데이터 뿐만 아니라 여러 정보가 포함되어 있습니다.
우선 여러 정보에서 데이터셋에 대한 설명 부분을 출력해보겠습니다.
print(data['DESCR']) # 사이킷런 데이터셋에서 데이터만 확인out:
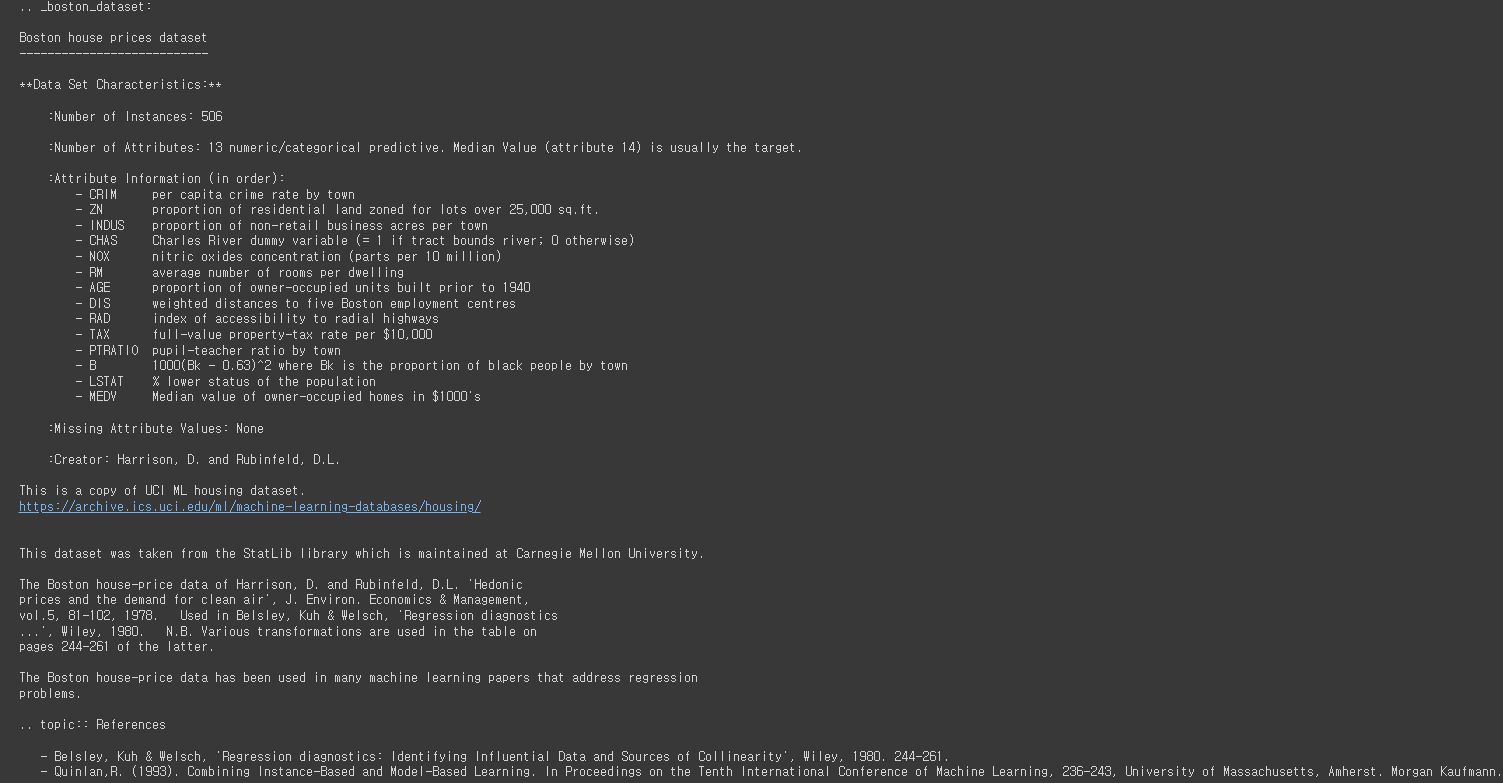
출력해보면 특히 컬럼 설명을 볼 수가 있습니다.
이제 본격적으로 데이터셋에서 데이터만 가져와보도록 하겠습니다.
그냥 가져오기보다는 데이터를 분석하기 편하도록 pandas의 DataFrame으로 가져오겠습니다.
df = pd.DataFrame(data['data'], columns=data['feature_names'])
df # 출력out:
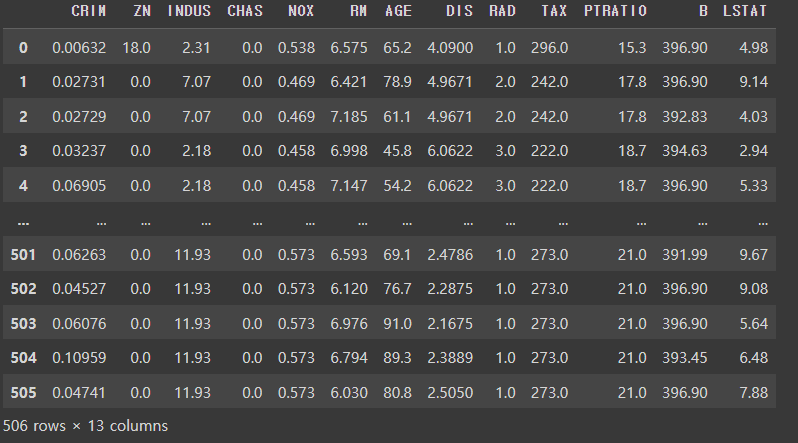
컬럼에 대한 정보를 정리해놓겠습니다.
- CRIM: 범죄율
- ZN: 25,000평방 피트 당 주거용 토지의 비율
- INDUS: 비소매(non-retail) 비즈니스 면적 비율
- CHAS: 찰스 강 더미 변수(통로가 하천을 향하면 1, 그렇지 않으면 0)
- NOX: 산화 질소 농도(천만 분의 1)
- RM: 주거 당 평균 객실 수
- AGE: 1940년 이전에 건축된 자가 소유 점유 비율
- DIS: 5개의 보스턴 고용 센터까지의 가중 거리
- RAD: 고속도로 접근성 지수
- TAX: 10,000달러 당 전체 가치 재산 비율
- PTRATIO: 도시 별 학생, 교사 비율
- B: 1000(Bk-0.63)^2 여기서 Bk는 도시 별 검정 비율
- LSTAT: 인구의 낮은 지위
- MEDV: 자가 주택의 중앙값(1,000달러 단위)
그런데 df에는 target 데이터가 포함되어 있지 않기 때문에 df에 파생변수를 만들어 target 데이터를 포함해주겠습니다.
df['MEDV'] = data['target']잘 처리가 되었는지 head()를 입력해보겠습니다.
df.head()out:

▷train / test 데이터셋 나누기
sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(
df.drop('MEDV'), 1), df['MEDV'], test_size=0.2, random_state=2)
▷평가지표
회귀 모델의 평가를 위한 지표는 실제 값과 회귀 예측 값의 차이를 통해 이뤄집니다.
회귀 평가지표 MAE, MSE, RMSE, RMSLE, MASE는 모두 값이 작을수록 회귀 성능이 좋은 것으로 볼 수 있습니다.
즉, 값이 작을수록 예측값과 실제값의 차이가 없다는 뜻이기 때문입니다.
1) MSE(Mean Squared Error)
- 에측값과 실제값의 차이에 대한 제곱에 대하여 평균을 낸 값
- 이상치에 민감하여 변동이 심한 데이터에 대해 모델 적합도를 올리는데 유리
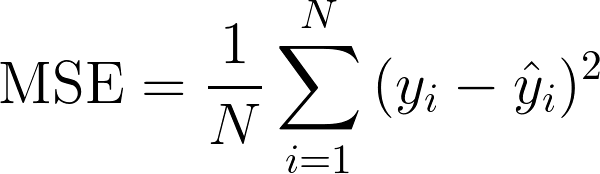
2) MAE(Mean Absolute Error)
- 예측값과 실제값의 차이에 대한 절댓값에 대하여 평균을 낸 값

3) RMSE(Root Mean Squared Error)
- 예측값과 실제값의 차이에 대한 제곱에 대하여 평균을 낸 후 루트를 씌운 값

위 평가지표들은 공식을 코드화해서도 사용할 수 있지만, 사이킷런을 통해서도 사용 가능합니다.
from sklearn.metrics import mean_absolute_error, mean_squared_error매개변수에는 (예측값, 실제값) 으로 넣어주면 됩니다.
mean_absolute_error(pred, actual)
mean_squared_error(pred, actual)
▷⭐모델 별 성능 확인을 위한 함수 정의
모델 별 성능 확인을 위한 함수를 정의해보겠습니다.
matplotlib.pyplot과 seaborn을 이욯해 시각적으로 예측값과 실제값을 plot위에 표시해주고 성능도 그래프로 나타내 주는 함수입니다.
import matplotlib.pyplot as plt
import seaborn as sns앞으로 여러 모델들을 살펴볼 건데 이를 계속 누적해서 plot에 표시하기 위해 딕셔너리 하나를 정의해주겠습니다.
my_predictions = {}많은 모델들의 mse를 barplot으로 살펴볼 예정이어서 barplot의 color들을 다음을 정의해놓고 랜덤하게 사용하려고 합니다.
colors = ['r', 'c', 'm', 'y', 'k', 'khaki', 'teal', 'orchid', 'sandybrown',
'greenyellow', 'dodgerblue', 'deepskyblue', 'rosybrown', 'firebrick',
'deeppink', 'crimson', 'salmon', 'darkred', 'olivedrab', 'olive',
'forestgreen', 'royalblue', 'indigo', 'navy', 'mediumpurple', 'chocolate',
'gold', 'darkorange', 'seagreen', 'turquoise', 'steelblue', 'slategray',
'peru', 'midnightblue', 'slateblue', 'dimgray', 'cadetblue', 'tomato']이제 예측값과 실제값을 plot에 표시해 주는 함수를 정의해 보겠습니다.
def plot_predictions(name_, pred, actual):
df = pd.DataFrame({'prediction': pred, 'actual': y_test})
df = df.sort_values(by='actual').reset_index(drop=True) # 실제값을 기준으로 오름차순(defalut) 정렬
plt.figure(figsize=(12, 9))
plt.scatter(df.index, df['prediction'], marker='x', color='r') # 예측값
plt.scatter(df.index, df['actual'], alpha=0.7, marker='o', color='black') # 실제값
plt.title(name_, fontsize=15)
plt.legend(['prediction', 'actual'], fontsize=12)
plt.show()이번에는 모델 별 mse를 barplot으로 나타내주는 함수를 정의해 보겠습니다.
def mse_eval(name_, pred, actual):
global my_prediction
global colors
plot_predictions(name_, pred, actual) # mse_eval() 함수를 실행하면 위에서 정의한 plot_prediction() 함수도 같이 실행되도록
mse = mean_squared_error(pred, actual)
my_predictions[name_] = mse # 'name' 키 값에 모델 이름과 해당하는 mse 값을 딕셔너리에 넣어줌
# my_predictions 딕셔너리의 아이템으로 정렬.
# 정렬은 딕셔너리{키:값}에서 x[1](=값)을 기준으로 정렬
# 내림차순
y_value = sorted(my_prediction.items(), key=lamda x: x[1], reverse=True)
# y_value는 [(키, 값), (키, 값), ...]행태로 정렬되어 있음
df = pd.DataFrame(y_value, columns=['model', 'mse'])
print(df)
# 그래프를 그릴 때 보기 좋으라고 상한과 하한을 설정
min_ = df['mse'].min() - 10
max_ = df['mse'].max() + 10
length = len(df)
plt.figure(figsize=(10, lenght))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=15)
bars = ax.barh(np.arange(len(df)), df['mse']) # 가로 막대 그래프
# mse 데이터에 index값과 value값을 각각 i와 v로 반복문
for i, v in enumerate(df['mse']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=15, fontweight='bold')
plt.title('MSE Error', fontsize=18)
plt.xlim(min_, max_)
plt.show()정의한 mse_eval() 함수는 모델의 학습시키고 예측한 다음에 사용할 예정입니다.
▷선형회귀(LinearRegression)
우선 앞으로 내용은 다음 도규먼트를 참고하면 도움이 될 겁니다 :)
sklearn.linear_model.LinearRegression
Examples using sklearn.linear_model.LinearRegression: Principal Component Regression vs Partial Least Squares Regression Principal Component Regression vs Partial Least Squares Regression Plot indi...
scikit-learn.org
from sklearn.linear_model import LinearRegressionmodel = LinearRegression(m_jobs=-1) # n_jobs: CPU코어를 전부 다 쓰겠다는 의미train 데이터셋을 이용해서 모델을 학습시키겠습니다.
model.fit(x_train, y_train)학습시킨 모델로 test 데이터를 이용해서 예측값(pred)을 만들겠습니다.
pred = model.predict(x_test)에측값을 만들었으니 위에서 정의한 mse_eval() 함수를 이용해서 성능 평가를 시각화 해보겠습니다.
mse_eval('LinearRegression', pred, y_test)out:
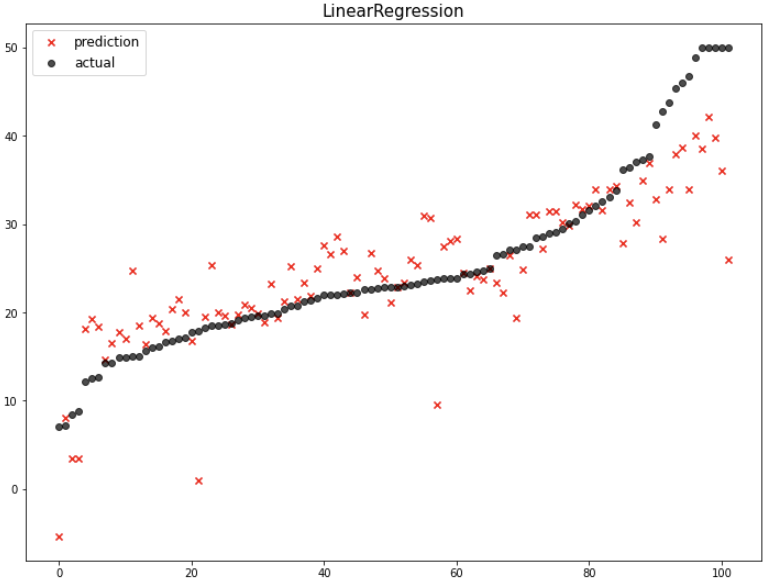

차차 여러 모델들을 다뤄보면서 성능을 비교해봅시다.
▷규제 (Regularization)
1) 규제 개념
정규화는 학습이 과대적합 되는 것을 방지하고자 하는 일종의 penalty를 부여하는 것입니다.

즉 과대적합된 모델에 정규화를 해줌으로써 복잡도를 낮춰서 성능을 높이기 위한 길인 새로운 데이터(test 데이터)에 대한 예측 성능을 높이는 것입니다.
과소적합 되었다는 것는 train 데이터가 모델 학습에 대해 충분한 설명력을 갖지 못함을 의미합니다. 즉, 모델이 너무 단순해서 애초에 예측을 잘하지 못한다는 것입니다.
과대적합 되었다는 것은 train 데이터에 너무 적합이 되어 새로운 데이터에 대해서는 예측을 잘하지 못하는 것을 의미합니다.
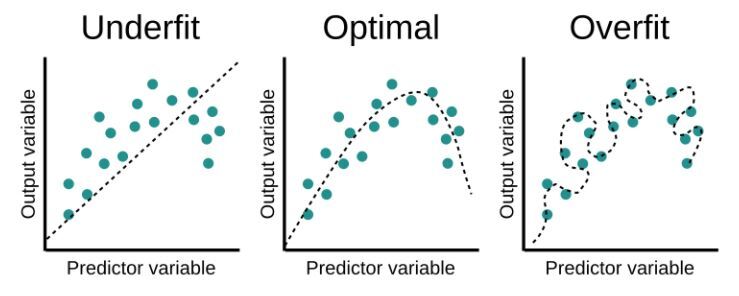
2) 규제 모델(Shrinkage methods) : Ridge, Lasso, ElasticNet
정규화 모델은 학습 시 계수(β)를 작게 학습하도록 유도합니다.
① Lasso
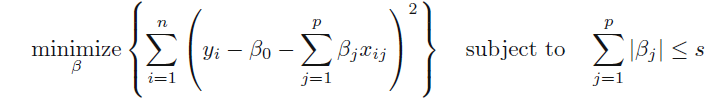
우선, Lasso는 L1 규제를 사용합니다.
Lasso는 중요하지 않은 변수에 대한 β를 정확하게 0으로 만들 수 있습니다.
즉, 변수를 완전히 제외할 수 있어서 변수 선택이 가능합니다.
위의 식에서 λ는 정규화 정도에 해당합니다.
즉 λ값이 클수록 정규화를 많이 해주는 것이고, λ값이 작을수록 정규화를 적게 해주는 것입니다.
정규화를 많이 해줄수록 모델이 많이 단순해집니다.
from sklearn.linear_model import Lassoλ에 해당하는 정규화 정도를 리스트로 만들겠습니다.
이를 for문으로 돌려 정규화 정도에 따른 성능을 비교할 예정입니다.
alphas = [100, 10, 1, 0.1, 0.01, 0.001]for alpha in alphas:
lasso = Lasso(alpha=alpha)
lasso.fit(x_train, y_train)
pred = lasso.predict(x_test)
mse_eval('Lasso(alpha={})'.format(alpha), pred, y_test)out:
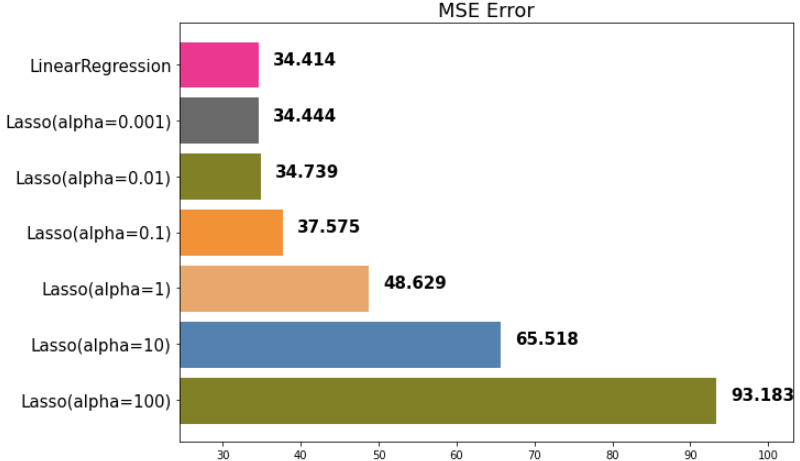
다시말해서 정규화 정도가 커질수록 변수의 계수 β가 작아집니다.
이를 정규화 정도를 100 준것과 0.001 준 것을 비교해서 확인해봅시다.
이때 coef_는 coefficient로 x변수의 계수 β를 의미합니다.
lasso_100 = Lasso(alpha=100)
lasso_100.fit(x_train, y_train)
lasso_pred_100 = lasso_100.predict(x_test)
lasso_0001 = Lasso(alpha=0.001)
lasso_0001.fit(x_train, y_train)
lasso_pred_0001 = lasso_0001.predict(x_test)각 변수의 계수를 함수로 정의해서 막대 그래프로 확인해봅시다.
def plot_coef(columns, coef):
coef_df = pd.DataFrame(list(zip(columns, coef)))
coef_df.columns=['feature', 'coef']
coef_df = coef_df.sort_values('coef', ascending=False).reset_index(drop=True)
fig, ax = plt.subplots(figsize=(9, 7))
ax.barh(np.arange(len(coef_df)), coef_df['coef'])
idx = np.arange(len(coef_df))
ax.set_yticks(idx)
ax.set_yticklabels(coef_df['feature'])
fig.tight_layout()
plt.show()plot_coef(x_train.columns, lasso_100.coef_)out:
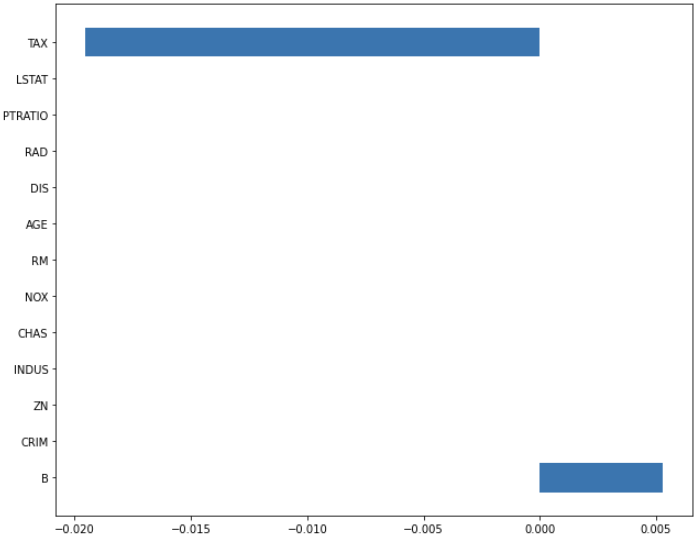
plot_coef(x_train.columns, lasso_0001.coef_)out:

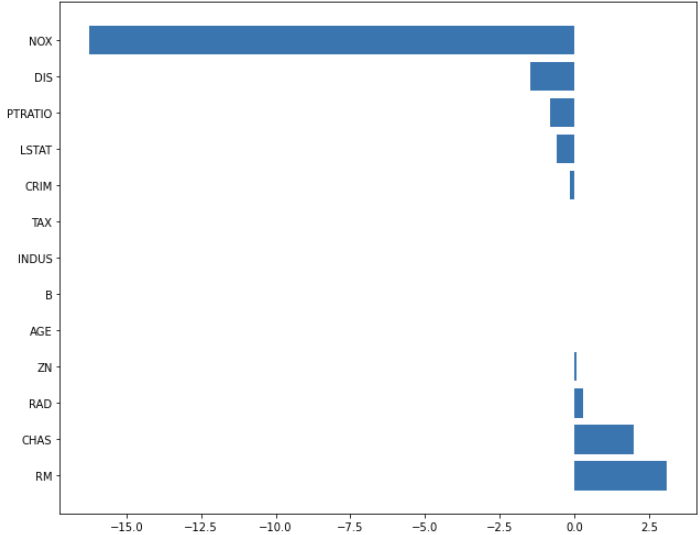
두 그래프를 보면 정규화 0.001 때 어느 정도 있던 변수의 계수가 정규화 100에서 즉 정규화 정도를 더 주었을 때 변수의 계수가 더욱 줄어들었습니다.
② Ridge

우선, Ridge는 L2 규제를 사용합니다.
Ridge는 중요하지 않은 변수의 크기를 0에 가깝게 줄입니다.
다만, β를 완전히 0으로 만들지는 못해서 변수선택 기법은 아닙니다.
다시 말해서, 변수를 완전히 배제할 수는 없다는 말입니다.
릿지는 x 변수 간 상관관계가 클 때 선형회귀보다 우수한 예측 성능을 보이는 것이 특징입니다.
from sklearn.linear_model import Ridgealphas = [100, 10, 1, 0.1, 0.01, 0.001, 0.0001]for alpha in alphas:
ridge = Ridge(alpha=alpha)
ridge.fit(x_train, y_train)
pred = ridge.predict(x_test)
mse_eval('Ridge(alpha={})'.format(alpha), pred, y_test)출력되는 그래프가 많은 관계로 마지막 barplot만 가져왔습니다.
out:
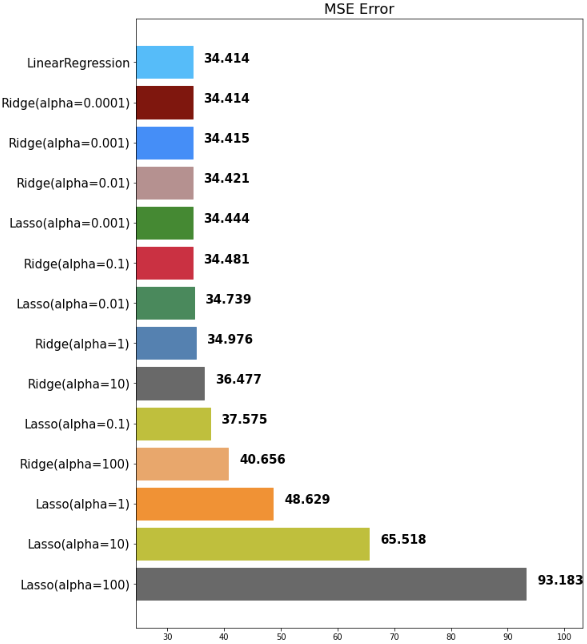
아까 언급했지만, mse가 작을수록 예측을 잘 하는 모델입니다.
ridge로도 위에서 만든 함수를 이용해서 변수 별 계수를 확인해봅시다.
ridge_100 = Ridge(alpha=100)
ridge_100.fit(x_train, y_train)
ridge_pred_100 = ridge_100.predict(x_test)
ridge_0001 = Ridge(alpha=0.001)
ridge_0001.fit(x_train, y_train)
ridge_pred_0001 = ridge_0001.predict(x_test)plot_coef(x_train.columns, ridge_100.coef_)out:
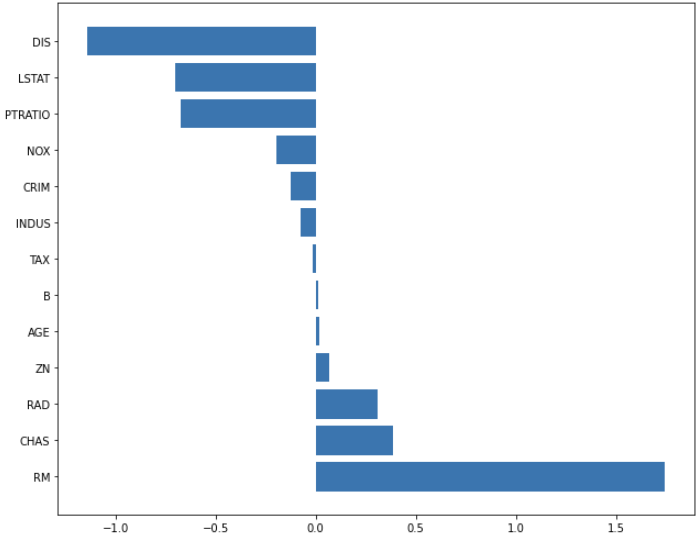
plot_coef(x_train.columns, ridge_0001.coef_)out:
③ ElasticNet
엘라스틱넷은 앞서 살펴본 Ridge와 Lasso를 결합한 모델로 볼 수 있습니다.
즉 L1 규제와 L2를 혼합해 사용하는 형태라고 볼 수 있습니다.
따라서 객체 속성으로 l1_ratio을 주는 것이 특징입니다.
l1_ratio = 0 (L2 규제만 사용)
l1_ratio = 1 (L1 규제만 사용)
0 < l1_ratio < 1 (L1과 L2 규제를 혼합 사용)
from sklearn.linear_model import ElasticNetL1 규제를 어느정도 적용할지를 리스트로 만들어줍니다.
이후에 for문으로 모두 적용해보고 이를 비교할 예정입니다.
ratios = [0.2, 0.5, 0.8]for ratio in ratios:
elastinet = ElasticNet(alpha=0.5, l1_ratio=ratio)
elastinet.fit(x_train, y_train)
pred = elastinet.predict(x_test)
mse_eval('Elasticnet(l1_ratio={})'.format(ratio), pred, y_test)out:

▷정규화(Normalize)
column간에 다른 min, max 값을 가지고 있는 경우 정규화를 통해 최소값/최대값의 척도를 맞춰주는 것입니다.
즉 상대적 크기에 대한 영향을 줄이기 위한 변환이라고 할 수 있습니다.
스케일 값이 큰 변수는 스케일 값이 작은변수에 비해 학습 시 영향이 더 클 수 있습니다.
간단한 예시를 하나 들어보겠습니다.
영화 평점 아시죠? 예를 들어 네이버는 10점 만점이고 넷플릭스는 5점 만점이라고 했을 때 우리는 네이버에서의 8점이 넷플릭스에서의 4점과 같다는 사실을 알고 있지만 머신러닝은 정규화를 해주어 알게 할 수 있습니다.
moive = {'naver': [2, 4, 6, 8], 'netflix': [1, 2, 3, 4, 5]}
movie = pd.DataFrame(data=moive)
movie # 출력out:
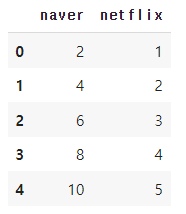
데이터프레임이 잘 만들어졌으니 이제 정규화를 해보겠습니다.
① MinMax 스케일링
MinMax 스케일링은 모든 feature 들의 데이터를 0~1에 있도록 조정해줍니다.
다만 이상치가 있는 경우 그 값에 휘둘리게 되어 변환된 값이 매우 좁은 범위로 압축될 수 있다는 점을 주의해야 합니다.

from sklearn.preprocessing import MinMaxScalermin_max_scaler = MinMaxScaler()min_max_movie = min_max_scaler.fit_transform(movie)
pd.DataFrame(min_max_movie, columns=['naver','netflix'])out:

② Robust 스케일링
Robust 스케일링은 중앙값(median)과 IQR(interquartile range)을 사용합니다.
그러므로 MinMax 스케일링보다 이상치에 덜 예민합니다.

from sklearn.preprocessing import RobustScalerrobust_scaler = RobustScaler()
robust_scaled - robust_scaler.fit_transform(x_train)import sklearn.preprocessing import RobustScaler▷표준화(Standardization)
표준화는 표준정규 분포의 속성의 갖도록 재조정되는 것입니다.
즉 평균을(mean)을 0으로 표준편차(std)를 1로 만들어주는 스케일러입니다.
다시말해서 데이터가 평균으로부터 얼마만큼 떨어져 분포하는지 표현하는 변환입니다.
① Standard 스케일링
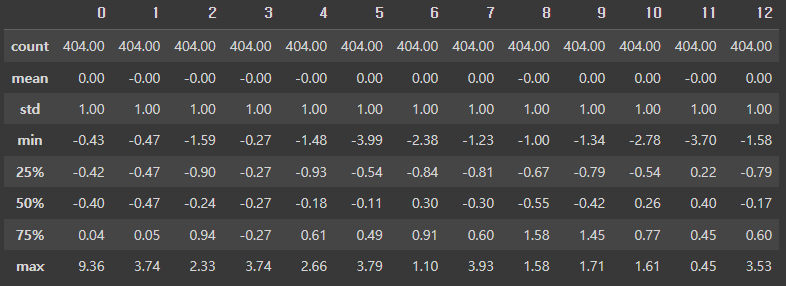
Standard 스케일링은 평균을 0으로 표준편차를 1로 놓고 모든 데이터를 조정합니다.
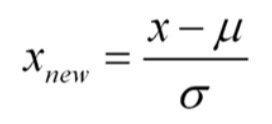
from sklearn.preprocessing import StandardScalerstd_scaler = StandardScaler()
std_scaled = std_scaler.fit_transform(x_train)
round(pd.DataFrame(std_scaled).describe(), 2) # 출력out:
▷사이킷런 파이프라인(Pipeline)
위에서 선형회귀도 공부하고 규제도 공부하고 정규화도 공부하고 표준화도 공부하고 여러 기법에 대해 공부했습니다.
이를 하나 하나 하나 적용할 수 밖에 없을까요?
사이킷런 파이프라인으로 한번에 적용 가능합니다.
from sklearn.pipeline import make_pipeline사이킷런 파이프라인을 이요해서 위에서 공부한 Standard 스케일링과 엘라스틱넷 규제를 한번에 해주겠습니다.
elasticnet_pipeline = make_pipeline(
StandardScaler(),
ElasticNet(alpha=0.1, l1_ratio=0.2)
)elasticnet_pred = elasticnet_pipeline.fit(x_train, y_train).predict(x_test)위에서 만든 시각화 함수를 다시 이용해서 성능을 비교해보겠습니다.
mse_eval('Standard ElasticNet', elasticnet_pred, y_test)out:

현재 데이터에서 standard 스케일링이 효과적인지 방금 파이프라인에서 standard 스케일링을 빼고 다시 모델을 만들어보겠습니다.
elasticnet_no_pipeline = ElasticNet(alpha=0.1, l1_ratio=0.2)
no_pipeline_pred = elasticnet_no_pipeline.fit(x_train, y_train).predict(x_test)
mse_eval('No Standard ElasticNet', no_pipeline_pred, y_test)out:
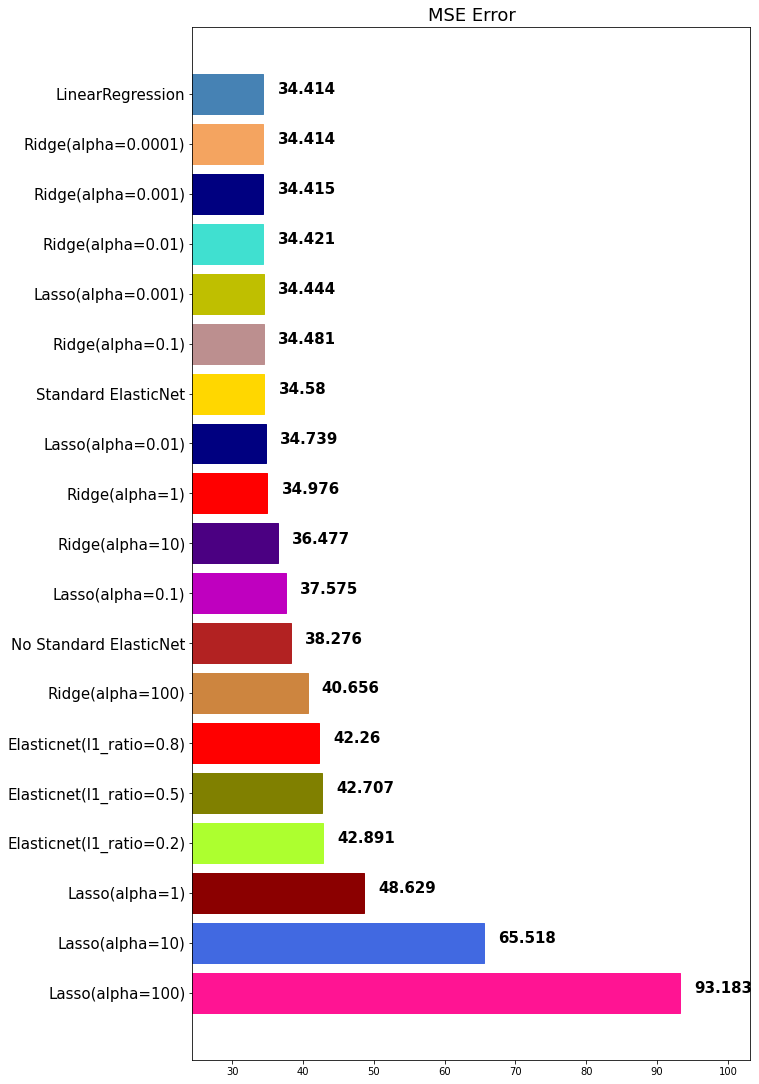
No Standard ElasticNet 보다 Standard ElasticNet이 좀 더 성능이 좋은 것을 확인할 수 있습니다.
다시 말해서 standard 스케일링이 도움이 되었다는 말이 되겠죠?
▷다항 회귀(Polynomial Regression)
다항 회귀에서는 다항식의 계수 간 상호작용을 통해 새로운 feature를 생성합니다.
즉 데이터가 단순한 직선 형태가 아닌 비선형 형태여도 선형모델을 사용하여 비선형 데이터를 학습할 수가 있습니다.
특성의 거듭제곱을 새로운 특성에 추가하고 확장된 특성을 포함한 데이터셋에 선형 모델을 학습합니다.
다음 도큐먼트를 참고하면 도움이 될 것 같습니다.
sklearn.preprocessing.PolynomialFeatures
Examples using sklearn.preprocessing.PolynomialFeatures: Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.24 Time-related feature engineering Time-related feature engi...
scikit-learn.org
from sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures(degree=2, include_bias=False) # bias를 포함X, (a+b)^2
poly_features = poly.fit_transform(x_train)이제 feature들의 기울기 값을 확인 가능합니다.
poly_featuresout:

이제 사이킷런 파이프라인을 이용해서 다항 회귀, standard 스케일링, elasticNet 규제를 한번에 적용해보겠습니다.
poly_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False),
StandardScaler(),
ElasticNet(alpha=0.2, l1_ratio=0.2)
)poly_pred = poly_pipeline.fit(x_train, y_train).predict(x_test)mse_eval('Poly Elasticnet', poly_pred, y_test)out:


확실히 좋은 poly ElasticNet의 성능을 확인할 수 있습니다.

여기까지 회귀에 대해 공부해보았습니다 :)
'빅데이터 인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝] ⑧ 오차 행렬(Confusion matrix) in 분류 (0) | 2022.08.19 |
|---|---|
| [머신러닝] ⑦ 분류(Classification) 모델 (0) | 2022.08.19 |
| [머신러닝] ⑤ 파이썬 파이토치(Pytorch) (0) | 2022.08.11 |
| [머신러닝] ④ 파이썬 텐서플로우(TensorFlow) (0) | 2022.08.11 |
| [머신러닝] ③ 타이타닉 데이터셋 실습 (0) | 2022.08.04 |
- Total
- Today
- Yesterday
- react
- 자바스크립트 기초
- 스타일 컴포넌트 styled-components
- next.js
- 딥러닝
- HTML
- 자바
- 자바스크립트
- 파이썬
- JSP
- 프론트엔드 기초
- frontend
- rtl
- jest
- styled-components
- 프론트엔드
- Python
- react-query
- CSS
- 프론트엔드 공부
- 타입스크립트
- TypeScript
- 데이터분석
- 디프만
- 인프런
- 프로젝트 회고
- testing
- 머신러닝
- 리액트 훅
- 리액트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |