
티스토리 뷰

▶분류(Classification)
말 그대로 Classification은 지도학습의 일종으로 기존에 존재하는 데이터의 카테고리 관계를 파악하고, 새로운 데이터의 카테고리를 스스로 판별하는 과정입니다.
종류에는 예를 들어 스팸메일인지 아닌지 분류하는 것처럼 단일 분류와 수능등급이 몇 등급에 해당하는지 판별하는 것처럼의 다중 분류가 있습니다.
1) Logistic Regression - 로지스틱 회귀
로지스틱은 독립 변수(x)의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는 데 사용되는 통계 기반으로서 이진 분류만 가능합니다.
그렇지만 3개 이상의 클래스에 대한 판별 즉 다중 분류를 진행하는 경우 아래와 같은 전략으로 판별이 가능합니다.
- one-vs-rest(0vR) : k개의 클래스가 존재할 때, 1개의 클래스를 제외한 다른 클래스를 k개 만들어 각각의 이진 분류에 대한 확률을 구하고, 총합을 통해 최종 클래스를 판별
- one-vs-one(0v0) : 4개의 계정을 구분하는 클래스가 존재한다고 할 때, 0vs1m 0vs2, 0vs3, ... , 2vs3까지의 Nx(N-1)/2 개의 분류기를 만들어 가장 많이 양성으로 선택된 클래스를 판별
참고로 0vR 전략을 선호합니다.
그럼 이제 모델을 학습시켜 봅시다.
from sklearn.linear_model import LogisticRegressionmodel = LogisticRegression()
prediction = model.fit(x_train, y_train).predict(x_test) # fit과 predict 한번에 입력
2) SGDClassifier - 확률적 경사 하강법 분류
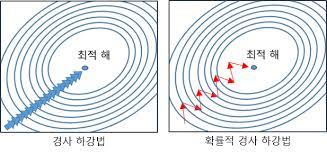
SGD는 stochastic gradient decent의 약자로 확률적 경사 하강법을 의미합니다.
전체 데이터가 아닌 랜덤하게 추출한 일부 데이터 한 개에 대해서 그래디언트를 계산하고 경사 하강 알고리즘을 적용하는 방법입니다.
아무래도 무작위로 추출한 샘플에 대해서 경사를 구하므로 학습 중간 과정에서 결과에 진폭이 크고 불안정합니다.
그렇지만 전체 데이터가 아닌 샘플 데이터 셋에 대해서만 경사(Gradient)를 계산하므로, 반복해서 다뤄야 할 데이터 수가 적어 속도가 매우 빠르다는 장점이 있습니다.
이제 학습을 시켜봅시다.
from sklearn.linear_model import SGDClassifiersgd = SGDClassifier()
sgd_pred = sgd.fit(x_train, y_train).predict(x_test)
3) KNN - 최근접 이웃 분류
KNN은 K-Nearest Neighbor로 지도 학습 알고리즘 중 하나입니다.
굉장히 직관적이고 간단하다는 특징이 있습니다.
따라서 클래스 수가 많은 다중 분류에서도 복잡도 부분에서 큰 어려움 없이 학습 수행이 가능합니다.
어떤 데이터가 주어지면 그 주변(이웃)의 데이터를 살펴본 뒤 데이터가 포함되어 있는 범주로 분류하는 방식입니다.
또 하나의 특징은 KNN은 훈련(training)이 따로 필요 없다는 것입니다.
밑에서 보겠지만 KNN 모델을 fit 시키는 과정은 다른 모델들의 fit과는 다르게 단지 train 데이터를 저장하는 것을 의미합니다.
from sklearn.neighbors import KNeighborsClassifierknc = KNeighborsClassifier()
knc_pred = knc.fit(x_train, y_train).predict(x_test)
위 사진에서 보이다싶이 이웃을 몇개로 잡을지를 n_neighbors 하이퍼파라미터로 정할 수가 있습니다.
해당 사진에서 빨간색 점이 새로운 데이터인데, k=3일 때는 3개의 이웃 중에 class B가 더 많기 때문에 새로운 데이터를 class B로 예측하게 됩니다.
하지만 k=6일 때를 보면 6개의 이웃 중 class A가 더 많기 때문에 새로운 데이터를 class A라고 예측하게 됩니다.
이렇듯 하이퍼파라미터 튜닝을 통해 전혀 다른 예측 결과를 얻게 됩니다.
참고로 default는 n_neighbors = 5 입니다.
knc = KNeighborsClassifier(n_neighbors=12)
4) SVM - 서포트 벡터 머신
SVM은 Suppoer Vector Machine으로 서포트 벡터 머신이라고 부르는 이진 선형 분류 모델입니다.
SVM은 결정 경계(Decision Boundary)를 통해 선을 정의하는 방식입니다.
즉 새로운 데이터가 나타나면 경계의 어느 쪽에 속하는지 확인해서 분류 과제를 수행하게 됩니다.
결국 이 결정 경계를 어떻게 정의하고 계산하는지가 중요한 포인트가 되겠습니다.

위 사진에서 볼 수 있듯이 두 가지 카테고리에 각각 데이터 셋들 사이에서 최외각에 있는 샘플들을 support vector라고 부릅니다.
다시말해 두 클래스로 부터 서로에게 가장 가까이 있는 샘플들을 서포트 벡터라고 하는 것입니다.
이 support vector를 통해 margin이 최대가 되는 선을 만드는 것입니다.
margin을 최대화한다는 계산 방식을 제외하면 로지스틱 회귀와 다를 점이 없습니다.
margin을 최대화한다는 계산 방식은 왜 필요한 걸까요?

바로 새로운 데이터가 들어왔을 때 최대화된 margin을 통하면 좀 더 정확한 분류를 할 수 있을 것 입니다.
위 그림을 보게 되면 새로운 데이터가 우리가 보기에도 초록색 클래스에 더 가깝습니다.
그렇지만 마진을 최대화하지 않는 분류 선 파란색 결정 경계에 따르면 분홍색 클래스에 속하는 것으로 예측하게 됩니다.
하지만 support vector에 의해 마진을 최대화한 결정 경계인 빨간색 선에 따르면 초록색 클래스에 속한다고 예측하게 됩니다.
이처럼 마진을 최대화한다는 계산 방식은 예측 결과에 많은 영향을 주게 됩니다.
이제 모델 학습을 시켜봅시다.
from sklearn.svm import SVCsvc = SVC()
svc_pred = svc.fit(x_train, y_train).predict(x_test)svc가 예측한 결과를 일부 추출해 보겠습니다.
svc_pred[:5]out:

위 결과가 어떻게 나오게 되었는지 알아보겠습니다. 참고로 0, 1, 2 중 하나로 예측됩니다.
svc.decision_function(x_test)[:5]out:
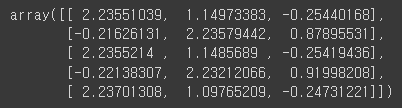
0, 1, 2 순으로 각각 행별로 확률을 나타냅니다.
이때 같은 행에서 가장 높은 확률인 target으로 예측하게 됩니다.
자세히 보면 위에서 첫 번째 예측 결과로 0이 나왔는데, 마찬가지로 첫 번째 행을 보게 되면 약 2.23으로 0이 가장 확률이 높아 0으로 예측하게 된 것입니다.
5) Decsion Tree - 의사결정나무

의사결정나무는 데이터를 분석하여 이들 사이에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타내며, 그 모양이 '나무'와 같다고 해서 의사결정나무라 불립니다.
질문을 통해 대상을 좁혀나가는 방식입니다.
의사결정나무는 분류(Classification)과 회귀(Regression) 모두 가능합니다.
from sklearn.tree import DecisionTreeClassifierdtc = DecisionTreeClassifier()
dtc_pred = dtc.fit(x_train, y_train).predict(x_test)의사결정나무를 학습시켰으니 이제 tree를 시각화 해봅시다.
from sklearn.tree import export_graphviz
from subprecess import calldef graph_tree(model):
export_graphviz(model, out_file='tree.dot')
call(['dot', '-Tpng', 'tree.dot', '-o', 'decistion-tree.png', '-Gdpi=600'])
return Image(filename='decistion-tree.png', width=700)graph_tree(dtc)out:

여기서 gini 계수는 불순도를 의미하며 계수가 높을수록 엔트로피가 크다는 뜻이 됩니다.
이때 엔트로피는 클래스가 얼마나 혼잡하게 섞여있는지를 뜻합니다.
의사결정나무는 정확하게 분류하려다 보니 과대적합이 되는 경우가 많습니다.
그러므로 모델을 학습시킬 때 최대깊이를 설정하는 하이퍼파라미터로 가지치기(Pruning)을 해주어야 합니다.
가지치기를 해줌으로써 새로운 데이터에 대한 일반화 성능을 올려주는 것입니다.
dtc = DecisionTreeClassifier(max_depth=3)
dtc_pred = dtc.fit(x_train, y_train).predict(x_valid)다시 한번 그래프를 시각화 해봅시다.
graph_tree(dtc)out:

최대 깊이가 3이 된 것을 확인할 수 있습니다.

여기까지 분류(Classification) 모델에 대해 알아보았습니다 :)
'빅데이터 인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝] ⑨ 앙상블(Ensemble) 모델 (0) | 2022.08.21 |
|---|---|
| [머신러닝] ⑧ 오차 행렬(Confusion matrix) in 분류 (0) | 2022.08.19 |
| [머신러닝] ⑥ 회귀(Regression) 분석 A to Z (0) | 2022.08.12 |
| [머신러닝] ⑤ 파이썬 파이토치(Pytorch) (0) | 2022.08.11 |
| [머신러닝] ④ 파이썬 텐서플로우(TensorFlow) (0) | 2022.08.11 |
- Total
- Today
- Yesterday
- frontend
- rtl
- TypeScript
- 머신러닝
- 인프런
- jest
- 디프만
- 딥러닝
- react
- styled-components
- 프론트엔드 기초
- 스타일 컴포넌트 styled-components
- 데이터분석
- 리액트
- 리액트 훅
- 프로젝트 회고
- 자바스크립트 기초
- 프론트엔드 공부
- 타입스크립트
- 자바스크립트
- next.js
- testing
- 프론트엔드
- react-query
- Python
- HTML
- CSS
- 자바
- 파이썬
- JSP
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |