
티스토리 뷰

▶ ANN을 위한 pyTorch 구현
+ ANN 복습
- Artificial Neural Network의 약자
- hidden layer을 포함한 인공신경망 기술
- ANN 동작 단계
- 1단계: 입력 계층에서 입력된 데이터에 대해 가중치 행렬을 곱하여 은닉 계층으로 보냄
- 2단계: 은닉 계층 내부에서 활성화 함수를 통해 데이터 가공
- 3단계: 은닉 계층에서 나온 데이터를 새로운 가중치 행렬을 곱해 출력 계층으로 보냄
- 4단계: 출력을 위한 활성화 함수를 반영하여 결과를 출력
필요한 라이브러리 import
import numpy as np
import torch
from torch import nn
import matplotlib.pyplot as plt
%matplotlib inline
Logistic Regression (PyTorch)
점들을 생성해서 그 점들을 분류하는 문제를 다뤄봅시다.
ⓛ 데이터셋 생성
n_data = torch.ones(1000,2) # 데이터를 1000개씩 두 줄 형태로 생성
# 데이터를 분류하기 위해 데이터를 생성
# torch.normal(mean, std) : 평균과 표준편차가 주어진 정규분포에서 랜덤하게 값을 추출하여 데이터셋을 만들어 줌
x0 = torch.normal(2*n_data, 1) # True 데이터
y0 = torch.zeros(1000)
x1 = torch.normal(-2*n_data, 1) # False 데이터
y1 = torch.ones(1000)
# 데이터를 묶어주는 작업
train_X = np.vstack([X0, X1])
train_y = np.vstack([y0, y1]).reshape(-1,1) # flatten
# 정답이 True/Fasle인 경우를 구분하기 위해 우선 정의
C1 = np.where(train_y == True)[0]
C0 = np.where(train_y == False)[0]
# torch를 이용해서 학습을 하기 위해서는 그에 맞는 형태로 정의를 해주어야 함
# numpy -> torch
# train_X는 float 형태이기 때문에 torch로 바꿀 때도 같은 형태로 정의
train_X, train_y = torch.from_numpy(train_X).float(), torch.from_numpy(train_y).float()
② 시각화
방금 만든 데이터를 plot 해 보겠습니다.
plt.figure(figsize = (10,8))
plt.plot(train_X[C1,0], train_X[C1,1], 'ro', alpha = 0.3, label='C1')
plt.plot(train_X[C0,0], train_X[C0,1], 'bo', alpha = 0.3, label='C0')
plt.xlabel(r'$x_1$', fontsize = 15)
plt.ylabel(r'$x_2$', fontsize = 15)
plt.legend(loc = 1, fontsize = 12)
plt.axis('equal')
plt.ylim([-5,5])
plt.show()
C0(파란색)로 표현되어 있는 데이터는 X1도 X2도 평균이 2, 표준편차 1의 정규분포를 따르는 데이터들
C1(빨간색)으로 표현되어 있는 데이터는 X1도 X2도 평균이 -2, 표준편차 1의 정규분포를 따르는 데이터들임을 확인할 수 있습니다.
우리가 하고자 하는 것은 C0와 C1을 하나의 hyperplane으로 분류를 하는 것!
③ DataLoader, TensorDataset 적용
- PyTorch에 적용을 하기 위해서는 DataLoader와 TensorDataset이라는 것을 활용해 주어야 함
- TensorDataset: 학습이 필요한 텐서들(데이터들)을 모아서 TensorDataset을 만들어 줌
- DataLoader: 어떤 데이터셋을 쓸건지, 얼마의 batch_size를 사용할건지, shuffle을 어떻게 할건지.. 등 이런 것들을 결정
from torch.utils.data import DataLoader, TensorDataset
def load_array(data_arrays, batch_size, is_train=True):
# 데이터셋과 데이터로더를 정의
dataset = TensorDataset(*data_arrays) # data_array형태로 데이터셋을 구성
dataloader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=is_train)
return dataloader방금 정의한 함수를 이용해서 데이터셋과 데이터로더를 만들어주겠습니다.
data_iter = load_array((train_X, train_y), batch_size=len(train_y)) # batch_size는 전체 데이터 통으로 사용여기까지 작업을 함으로써 학습을 하기 위한 형태로 데이터를 정의했다고 할 수 있습니다.
④ class 정의
모델의 class를 정의해주어야 합니다.
이때 클래스 내부에 들어가게 되는 함수는 두 가지입니다.
- init 함수
- 모델에 instance를 생성했을 때 이 인스턴스가 갖게 되는 성질을 정의
- torch.nn.Linear(in_features, out_features,...)
- 들어오는 float32형 input 데이터에 대해 y=wx+b 형태의 선형 변환을 수행하는 메소드
- 우리는 2개의 데이터 종류를 넣어서 1개의 종류로 구분하는 문제이므로 (2, 1) 입력
- torch.nn.Sigmoid()
- 시그모이드 함수 적용하는 메소드
- 최종적으로 결론을 내는 형태로 구현
- forward 함수
- layer들간의 관계를 정의
class LogisticRegressionModel(torch.nn.Module):
# init과 forward method
# init method: 모델에 instance를 생성했을 때 이것이 갖게 되는 성질을 정의
def __init__(self):
super(LogisticRegressionModel, self).__init__() # nn.Module 내에 있는 메소드들을 상속받게 함
# layer를 본격적으로 정의
self.layer = torch.nn.Linear(2, 1)
self.sigmoid = torch.nn.Sigmoid()
# forward method: layer들간의 관계를 정의
def forward(self, inputs):
outputs = self.layer(inputs) # 위에서 정의 layer에 input 데이터를 넣었을 때 나오는 값
return self.sigmoid(outputs) # 최종적으로 시그모이드 함수를 씌운 값을 리턴
model_logR = LogisticRegressionModel()
+ GPU를 사용하는 경우라면
if torch.cuda.is_available():
train_X, train_y = train_X.cuda(), train_y.cuda()
model_logR.cuda()
⑤ weight와 bias를 초기화
print(model_logR.layer.weight.data)
print(model_logR.layer.bias.data)
⑥ Optimizer 정의
이번에는 SGD(확률적 경사 하강법)으로 optimizer를 정의해 주었습니다.
optimizer_logR = torch.optim.SGD(model_logR.parameters(), lr=0.05)model_logR.parameters()를 한번 출력해보면
model_logR.parameters
모델의 파라미터 정보에는 layer가 어떤 것인지, 어떤 활성화 함수를 사용하는지에 대한 내용이 포함되어있다!
⑦ 학습
num_epochs = 200
for epoch in range(num_epochs):
for X, y in data_iter: # data_iter를 돌면서 학습을 하는 과정을 작성
predict_logR = model_logR(train_X) # 예측값 도출
loss_logR = torch.nn.functional.binary_cross_entropy(predict_logR, train_y)
optimizer_logR.zero_grad() # 0으로 초기화
loss_logR.backward() # 역전파 진행
optimizer_logR.step() # weight를 업데이트
⑧ 구한 weights를 시각화
# 학습을 통해 얻은 weights들을 변수에 저장
w1 = model_logR.layer.weight[0][0].item()
w2 = model_logR.layer.weight[0][1].item()
b = model_logR.layer.bias.item()
print(w1, w2, b)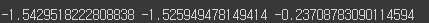
xp = np.arange(-4, 4, 0.01).reshape(-1, 1)
yp = - w1 / w2 * xp - b / w2
train_X, train_y = train_X.cpu(), train_y.cpu()
plt.figure(figsize = (10,8))
plt.plot(train_X[C1,0], train_X[C1,1], 'ro', alpha = 0.3, label='C1')
plt.plot(train_X[C0,0], train_X[C0,1], 'bo', alpha = 0.3, label='C0')
plt.plot(xp, yp, 'g', linewidth = 3, label = 'Logistic Regression')
plt.xlabel(r'$x_1$', fontsize = 15)
plt.ylabel(r'$x_2$', fontsize = 15)
plt.legend(loc = 1, fontsize = 12)
plt.axis('equal')
plt.ylim([-4,4])
plt.show()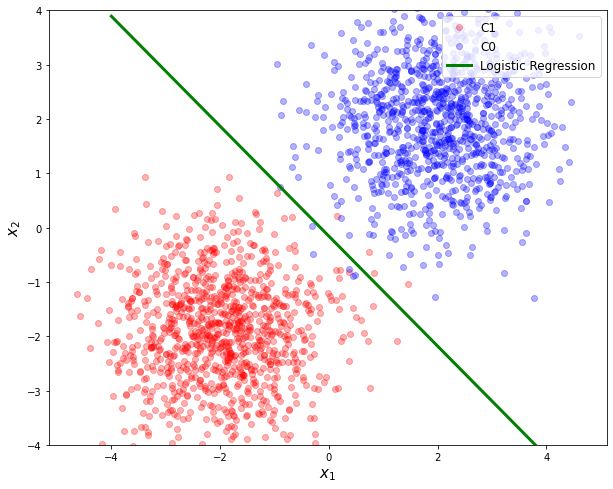
728x90
LIST
'빅데이터 인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝] CNN(Convolutional Neural Network) A to Z (1) | 2022.11.26 |
|---|---|
| [딥러닝] MLP를 위한 PyTorch 구현 (0) | 2022.11.26 |
| [딥러닝] 딥러닝에서의 일반화(Regularization) (0) | 2022.11.25 |
| [딥러닝] 딥러닝에서의 최적화(Optimization) (0) | 2022.11.25 |
| [딥러닝] MLP(Multi-Layer Perceptron) A to Z (0) | 2022.11.25 |
250x250
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 자바
- jest
- JSP
- HTML
- 디프만
- 인프런
- next.js
- rtl
- 데이터분석
- 프로젝트 회고
- 프론트엔드
- testing
- 프론트엔드 공부
- react-query
- 자바스크립트 기초
- react
- 리액트
- 자바스크립트
- 프론트엔드 기초
- 리액트 훅
- CSS
- frontend
- 딥러닝
- Python
- TypeScript
- 머신러닝
- styled-components
- 스타일 컴포넌트 styled-components
- 파이썬
- 타입스크립트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
글 보관함