
티스토리 뷰

▶딥러닝에서의 일반화(Regularization)
→ 과적합(Overfitting) 문제를 해결하자
1. 일반적인 방법
- Big Data / Data augmentation
- 과적합을 해결하는 가장 쉬운 방법으로, 데이터셋의 규모를 키우는 방법
- L1/L2 regularization
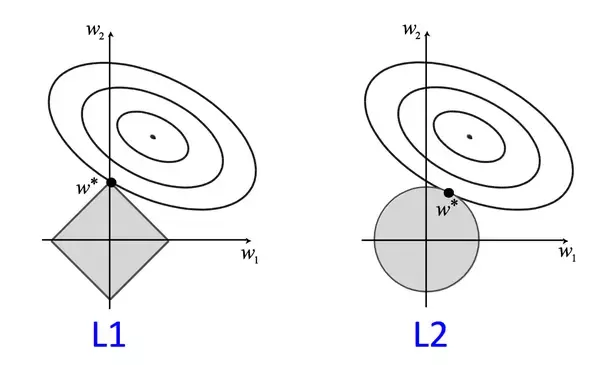
2. Dropout
- 각각의 iteration 마다 일정 비율을 정해서 랜덤하게 노드들을 select
- 이 select된 노드들은 제외해서 학습 진행
- 특정 컬럼들을 0으로 바꿈
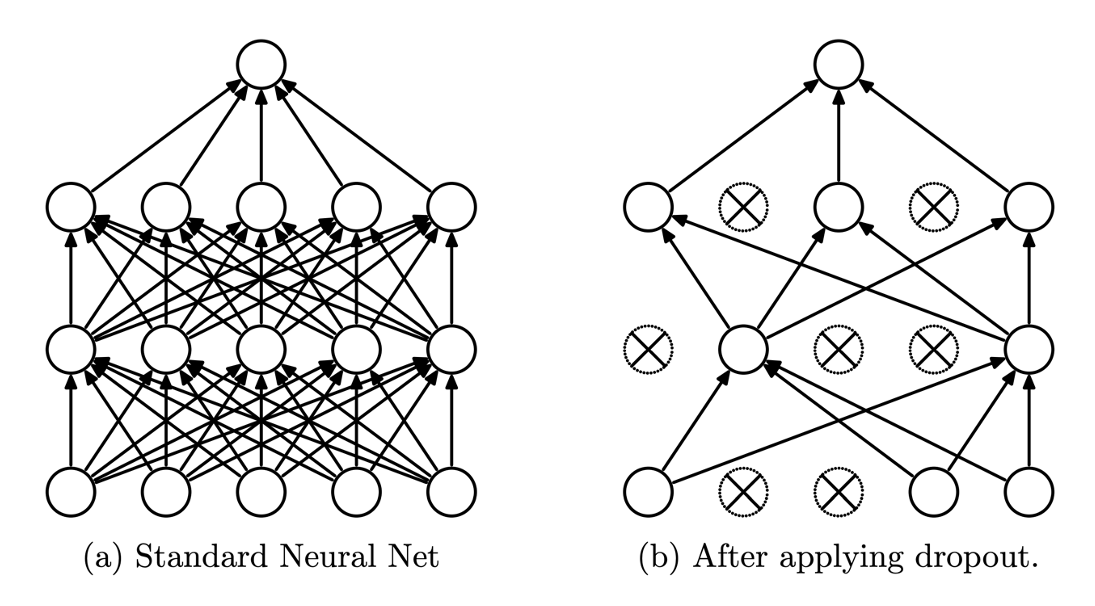

Dropout은 training과 testing 과정에서 어떻게 적용이 되는가?
- Dropout은 training 과정에서만 적용
- testing 상황에서는 모든 node들을 돌려놓고 test를 진행
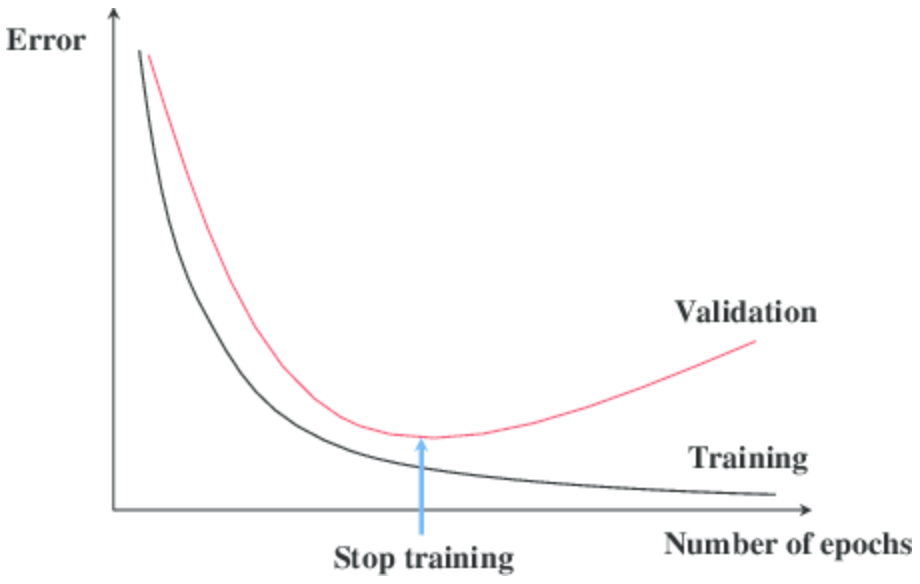
3. Early Stopping
- Validation 데이터셋의 성능이 약화되는 것을 확인하면 즉시 학습 종료
4. Batch Normalization
Inernal Covariance Shift
- Neural Network가 여러 layer들로 구성되어 있다고 할 때
- 각 layer마다의 input 데이터 값의 분포가 너무 달라지기 때문에 이 network가 학습을 하는 데에
- 퍼포먼스가 상당히 떨어지는 단점
- 이를 해결 하기 위해 중간중간 Batch Normalization하는 과정이 적용
Batch Normalization
- activation function의 input을 normalization
- 학습시 내부에서 평균과 분산을 조정하는 과정
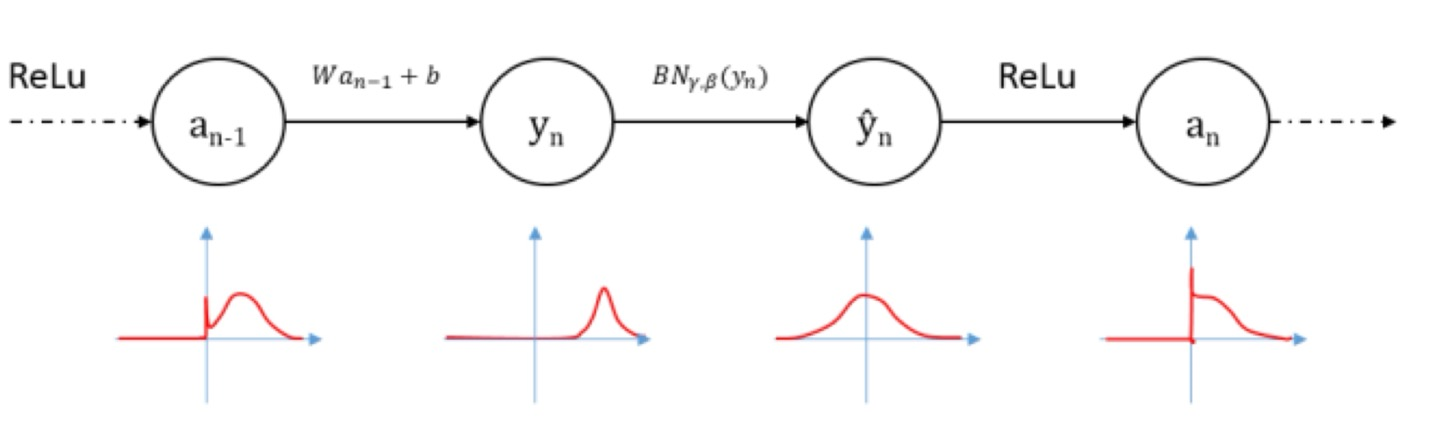
위 그림에서 BN이 배치 정규화를 의미하는데 activation function을 적용하기 전에 정규화를 적용해 줍니다.
두 번째 그래프를 정규화 해주어 평균과 분산을 맞춰주는 작업을 한 것을 확인할 수 있습니다.
참고로, 활성화 함수를 잘 활용하려면 들어오는 입력 데이터들이 특정 구간 안에 모두 포함되는 것이 좋습니다.
따라서 배치 정규화를 통해 들어오는 입력 데이터들이 구간에 모두 포함될 수 있도록 조정을 해주게 됩니다.
5. Initialization
처음에 weight를 어떻게 초기화?
Gradient descent를 할 때 제일 처음 weight를 초기화 한다고 했습니다.
초기화 하는 방법의 종류는 다음고 같습니다.
- Constant (zeros, ones, constant)
- 상수들로 초기화
- Linear Algebra (Orthogonal, Identity)
- 직교행렬, 단위행렬의 값들로 초기화
- Probability (Uniform, Normal)
- 분포에 따라서 초기화
- Lecun, He, ...
- 연구자들이 만든 방법으로 초기화
728x90
LIST
'빅데이터 인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝] MLP를 위한 PyTorch 구현 (0) | 2022.11.26 |
|---|---|
| [딥러닝] ANN을 위한 PyTorch 구현 (1) | 2022.11.26 |
| [딥러닝] 딥러닝에서의 최적화(Optimization) (0) | 2022.11.25 |
| [딥러닝] MLP(Multi-Layer Perceptron) A to Z (0) | 2022.11.25 |
| [딥러닝] CNN(Convolutional Neural Network)과 MLP(Multi Layer Perceptron) 의 차이 (0) | 2022.11.19 |
250x250
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 프론트엔드
- frontend
- HTML
- TypeScript
- styled-components
- 머신러닝
- 스타일 컴포넌트 styled-components
- 리액트 훅
- 디프만
- 프론트엔드 공부
- jest
- Python
- rtl
- CSS
- JSP
- 파이썬
- 자바
- react
- next.js
- testing
- react-query
- 자바스크립트 기초
- 데이터분석
- 딥러닝
- 자바스크립트
- 프로젝트 회고
- 타입스크립트
- 인프런
- 프론트엔드 기초
- 리액트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함