
티스토리 뷰

▶Oxford Pets Dataset 실습 - https://www.robots.ox.ac.uk/~vgg/data/pets/
Visual Geometry Group - University of Oxford
www.robots.ox.ac.uk
Oxford Pets Dataset은 강아지와 고양이를 분류하기 위한 데이터셋으로 이미지파일들과 xml파일로 이미지의 속 동물의 정보를 담고 있는 데이터로 이루어져 있습니다.

결론적으로, 우리는 강아지와 고양이를 분류하는 모델을 만들 것입니다.
1) 필요한 라이브러리 import
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
2) csv 파일 불러오기
annotations 파일 속 list.txt에는 이미지 파일들의 이름과 동일하게 file_name과 id, species breed 정보를 담고 있습니다.
참고로 해당 파일은 txt 파일로 띄어쓰기로 구분되어있음을 기억합시다.
df = pd.read_csv('./data/annotations/list.txt', skiprows=6, delimiter=' ', header=None)
df.columns = ['file_name', 'id', 'species', 'breed']
보시다싶이 위에서 6번째 줄까지는 필요없는 내용이라 skiprows=6을 해줍니다.
3) 데이터셋 확인해 보기
우선 df를 찍어봅시다.
dfout:

species의 value_counts()를 찍어봅시다.
print(df['species'].value_counts().sort_index())out:

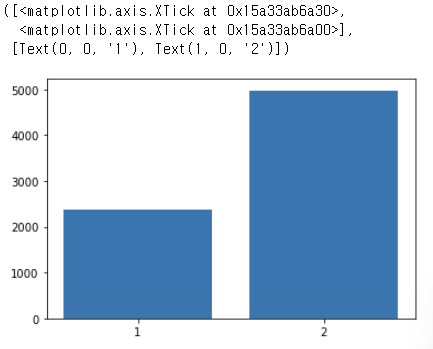
이미지 데이터에 고양이가 2371장, 개가 4978장 있다는 것을 확인할 수 있습니다.
조금 편향되어 있어 보입니다.
방금 print 해본 것을 시각화해 볼까요?
value_counts = df['species'].value_counts().sort_index()
plt.bar(range(len(value_counts)), value_counts.values, align='center')
plt.xticks(range(len(value_counts)), value_counts.index.values)out:
이제는 'id' 즉 종에 대해서 시각화 해보겠습니다.
참고로 종은 강아지와 고양이 합쳐서 index를 이루고 있습니다.
- tight_layout(pad=1.08, h_pad=None, w_pad=None, rect=None) : 자동으로 명시된 여백(padding)에 관련된 서브플롯 파라미터를 조정한다. 입력 없이 사용할 경우 기존에 세팅된 기본값을 이용하여 자동으로 레이아웃을 설정한다.
- pad : figure의 모서리와 서브플롯의 모서리 사이의 여백(padding)을 설정한다.
- h_pad, w_pad : 서로 인접한 서브플록(subplot)의 모서리(edge)의 높이 및 너비의 여백을 설정한다.
- rect : 서브플롯을 넣기 위한 사각형을 설정하며(왼쪽, 모서리, 오른쪽, 위쪽)의 값을 입력 받는다.
value_counts = df['id'].value_counts().sort_index()
plt.bar(range(len(value_counts)), value_counts.values, align='center')
plt.xticks(range(len(value_counts)), value_counts.index.values)
plt.tight_layout()out:

개와 고양이 합쳐서 종이 총 37개가 존재하는 것을 확인할 수 있습니다.
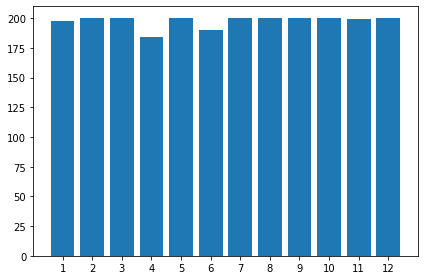
고양이 종과 강아지 종을 따로따로 시각화 해봅시다.
# 고양이의 종만 출력
value_counts = df[df['species'] == 1]['breed'].value_counts().sort_index()
plt.bar(range(len(value_counts)), value_counts.values, align='center')
plt.xticks(range(len(value_counts)), value_counts.index.values)
plt.tight_layout()out:
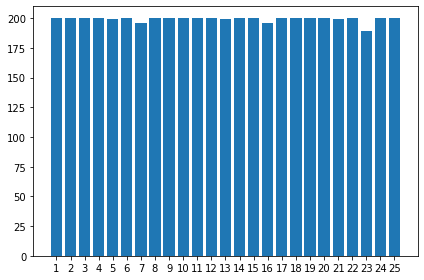
# 강아지의 종만 출력
value_counts = df[df['species'] == 2]['breed'].value_counts().sort_index()
plt.bar(range(len(value_counts)), value_counts.values, align='center')
plt.xticks(range(len(value_counts)), value_counts.index.values)
plt.tight_layout()out:
4) 이미지 파일 불러오기
지금 불러올 파일은 종 3가지입니다.
- 이미지 파일
- 이미지 별로 고양이/개의 정보를 담고 있는 xml 파일
- 배경 분리를 위한 trimap 파일
우리는 glob 라는 라이브러리를 통해 해당 디렉토리에 있는 파일들을 한꺼번에 가져올 겁니다.
우선 해당 파일들이 있는 경로를 변수에 저장해 놓겠습니다.
참고로 파이썬에서는 문자열 내부에서 역슬러시(\)를 사용하기 위해서는 \\(역슬러시 역슬러시)로 입력해주어야 합니다.
image_dir = 'data\\images\\'
bbox_dir = 'data\\annotations\\xmls\\'
seg_dir = 'data\\annotations\\trimaps\\'파일 경로를 알기 위한 os 라이브러리와 디렉토리에서 모든 파일들을 불러오기 위한 glob 라이브러리를 import 하겠습니다.
import os
from glob import glob우선 저장해둔 image_dir 변수와 glob 라이브러리를 이용하여 모든 이미지 파일을 불러오겠습니다.
image_files = glob(image_dir + '*.jpg') # 해당 디렉토리에서 모든 jpg 파일 불러옴잘 불러왔는지 확인해볼까요?
image_files[:5]out:
잘 불러온 것 같습니다.
이제 비슷한 방법으로 bbox_dir에 있는 파일들을 불러오겠습니다.
bbox_files = glob(bbox_dir + '*.xml')
이제 trimap 이미지를 불러와야 합니다.
그런데 이 trimap 이미지를 원본 이미지 파일과 매칭하여 불러오려고 합니다.
import cv2 # 이미지 파일을 읽고 쓰기 위한 라이브러리지금 이미지 파일과 seg파일을 유심히 살펴보면 다음과 같습니다.


보시다싶이 매칭되는 trimap 파일은 파일 이름이 같습니다.
다른 점이라고는 확장자 명이 다릅니다.
images_path = image_files[2] # 사진 아무거나 선택
print(image_path) # 출력해보기
# seg 파일과 image 파일들이 이름이 같아서 확장면만 바꾸면 동일하게 매칭 가능
# image_dir -> seg_dir -> 'xml'
seg_path = images_path.replace(image_dir, seg_dir).replace('jpg', 'png')
print(bbox_path) # 출력해보기out:


잘 매칭되었음을 확인해 볼 수 있습니다.
이제 매칭된 이미지파일과 trimap을 같이 출력해 볼까요?
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
seg_map = cv2.imread(seg_path, cv2.IMREAD_GRAYSCALE)
plt.figure(figsize=(15,15))
plt.subplot(121)
plt.imshow(image)
plt.subplot(122)
plt.imshow(seg_map)
plt.show()out:

+) bndbox 좌표를 이용해 이미지에 사각형 그리기
xml 파일을 좀 자세히 보겠습니다.
파일을 하나 열어보면 다음과 같이 태그(tag) 형식으로 존재합니다.

그런데 이 중에서 이미지 속 좌표를 나타내는 태그가 있습니다.
이 부분을 파싱하여 이미지에 사각형을 그려보려고 합니다.

필요한 라이브러리를 import 하겠습니다.
import xml.etree.ElementTree as et # xml 파싱
from matplotlib.patches import Reactangle # 도형을 그리기 위한 라이브러리위에서 매칭했던 방법과 동일하게 xml 파일과 이미지 파일을 매칭시키겠습니다.
images_path = image_files[2]
print(images_path)
bbox_path = images_path.replace(image_dir, bbox_dir).replace('jpg', 'xml')
print(bbox_path)out:

잘 매칭되었습니다.
지금 이미지가 어떻게 되어있는지를 확인해볼 겸 이를 출력해보겠습니다.
image = cv2.imread(image_path)
print(image.shape) # 세로, 가로, 채널
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)out:

세로는 300px, 가로는 279px, 컬러 채널로 되어있음을 확인했습니다.
이제 et 라이브러리를 이용하여 xml을 파싱해 보겠습니다.
tree = et.parse(bbox_path) # xml 경로를 넣어서 파싱
xmin = float(tree.find('/object/bndbox/xmin').text)
xmax = float(tree.find('/object/bndbox/xmax').text)
ymin = float(tree.find('/object/bndbox/ymin').text)
ymax = float(tree.find('/object/bndbox/ymax').text)
rect_x = xmin
rect_y = ymin
rect_w = xmax-xmin
rect_h = ymax-ymin이제 이미지와 함께 사각형을 그려보겠습니다.
rect = Rectangle((rect_x, rect_y), rect_w, rect_h, fill=False, color='red')
plt.axes().add_patch(rect)
plt.imshow(image)
plt.show()out:

5) 교차 검증
데이터의 수가 적은 경우 데이터 중의 일부인 검증 데이터의 수도 적기 때문에 검증 성능의 신뢰도가 떨어질 수밖에 없습니다.
그렇다고 검증 데이터의 수를 증가시키면 학습용 데이터의 수가 적어지므로 정상적인 학습이 되지 않습니다.
그렇다면 데이터 수가 적을 때는 어떻게 해야할까요?
다시말해 과적합을 해결하기 위한 방법은 무엇일까요?
바로 교차 검증을 이용합니다.
교자 검증을 따로 정리한 글을 함께 보며 적용해 봅시다.
[머신러닝] ⑩ 교차 검증(Cross Validation)
▶교차 검증(Cross Validation) 보통은 train set으로 모델을 훈련, test set으로 모델을 검증합니다. 하지만 이 방법은 고정된 test set을 통해 모델의 성능을 검증하고 수정하는 과정을 반복하게 되면서 결
doeunn.tistory.com
가장 대표적인 교차검증 방법인 KFold 의 라이브러리를 import 해보겠습니다.
from sklearn.model_selection import KFold이제 어떻게 교차검증을 진행할 건지에 대해 캡슐화하여 객체를 만들어주겠습니다.
kf = KFold(n_splits=5, shuffle=True, random_state=40)이제 df 에 fold라는 컬럼을 만들어 fold 번호를 입력해줄 건데 우선 초기화부터 해놓겠습니다.
df['fold'] = -1이제 fold 번호를 매겨주겠습니다.
참고로 index 번호는 1부터 시작하겠습니다.
for idx, (t, v) in enumerate(kf.split(df), start=1):
print(t, v, len(v))
df.loc[v, 'fold'] = idx # fold 번호 매기기out:

이제 조금 부족한 5번 fold를 제외하고 시각화를 해보겠습니다.
value_counts = df[df['fold'] != 5]['id'].value_counts().sort_index()
plt.bar(range(len(value_counts)), value_counts.values, align='center')
plt.xticks(range(len(value_counts)), value_counts.index.values)
plt.tight_layout()
plt.show()out:

고르지 못한 모습을 볼 수 있습니다.
이는 KFold의 문제점이라고 볼 수 있는 일정한 간격으로만 잘라서 사용한다는 점 때문으로 볼 수도 있습니다.
이를 보완해서 나온 KFold가 있습니다.
# StratifiedKFold
StratifiedKFold의 경우 target에 속성값의 개수를 동일하게 하여 가져감으로써 kfold 같이 데이터가 한곳으로 몰리는 것을 방지합니다.
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=40)
df['fold'] = -1
for idx, (t, v) in enumerate(skf.split(df, df['id']), 1): # df['id']로 평탄화
print(t, v, len(v))
df.loc[v, 'fold'] = idx # fold 번호 매기기다시 시각화를 해보겠습니다.
value_counts = df[df['fold'] != 5]['id'].value_counts().sort_index()
plt.bar(range(len(value_counts)), value_counts.values, align='center')
plt.xticks(range(len(value_counts)), value_counts.index.values)
plt.tight_layout()
plt.show()out:

이전보다 좀 더 균일해진 모습을 확인할 수 있습니다.
방금 fold 컬럼까지 추가한 데이터프레임을 csv 파일로 저장해 두겠습니다.
df.to_csv('data/kfolds.csv', index=False)
6) 데이터로더
데이터로더는 batch 기반의 딥러닝 모델 학습을 위해 데이터를 효율적으로 읽어오는 역할을 수행합니다.
참고하고 좋은 데이터로더 구현과 관련된 도큐먼트는 다음과 같습니다.
tf.keras.utils.Sequence | TensorFlow v2.10.0
Base object for fitting to a sequence of data, such as a dataset.
www.tensorflow.org
필요한 라이브러리를 import 하겠습니다.
from tensorflow import keras
import pandas as pd
import numpy as np이제 데이터로더 클래스(class)를 정의해 주겠습니다.
import math
import cv2
import matplotlib.pyplot as pltclass DataGenerator(keras.utils.Sequence):
def __init__(self, batch_size, csv_path, fold, image_size, mode-'train', shuffle=True):
self.batch_size = batch_size
self.csv_path = csv_path
self.fold = fold
self.image_size = image_size
self.mode = mode
self.shuffle = shuffle
self.df = pd.read_csv(csv_path)
if self.mode = 'train':
# 들어온 fold 번호와 다른 fold들을 train 시킴
self.df = self.df[self.df['fold'] != self.fold]
elif self.mode == 'val':
self.df = self.df[self.df['fold'] == self.fold]
self.on_epoch_end()
# frac: 전체 row에서 몇 %의 데이터를 return할 것인지를 설정
def on_epoch_end(self):
if self.shuffle:
self.df = self.df.sample(frac=1).reset_index(drop=True)
def __len__(self):
return math.ceil(len(self.df) / self.batch_size)
def __getitem__(self, idx): # 객체를 만들고 idx로 접근해서 호출하는 메소드
start = idx * self.batch_size
end = (idx+1) * self.batch_size
data = self.df.iloc[start:end]
batch_x, batch_y = self.get_data(data)
return np.array(batch_x), np.array(batch_y)
def get_data(self, data):
batch_x = []
batch_y = []
for _, r in data.iterrows(): # _는 사용하지 않겠다는 의미. 여기서는 idx에 해당함. 즉 데이터만 사용
file_name = r['file_name']
image = cv2.imread(f'data/images/{file_name}.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (self.image_size, self.image_size)) # 각기 다른 크기를 하나로 맞춰줌
image = image / 255 # 정규화
label = int(r['species']) - 1 # 나중에 인덱스로 사용하기 위해 -1 해줌
batch_x.append(image) # 이미지
batch_y.append(label) # 이미지에 대한 정답 레이블
return batch_x, batch_y이제 방금 정의한 class를 가지고 train_generator를 저장해 놓습니다.
csv_path = 'data/kfolds.csv'
train_generator = DataGenerator(
batch_size=9,
csv_path = csv_path,
fold=1,
image_size = 256
mode = 'train',
shuffle = True
)이제 동작 시켜서 이미지와 정답 레이블이 잘 출력되는지 확인해 보겠습니다.
class_name = ['Cat', 'Dog']
for batch in train_generator:
X, y = batch # X값은 이미지, y값은 정답 레이블
plt.figure(figsize=(15,15))
for i in range(9):
ax = plt.subplot(3,3,i+1)
plt.imshow(X[i])
plt.title(class_name[y[i]])
plt.axis('off')
breakout:


여기까지 Oxford Pets Dataset 실습을 해보았습니다 :)
'빅데이터 인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝] CNN(Convolutional Neural Network) 모델 구현 (0) | 2022.09.18 |
|---|---|
| [딥러닝] CNN(Convolutional Neural Network) 알아보기 (0) | 2022.09.18 |
| [딥러닝] 역전파(Backpropagation) - 경사하강법 & 활성화 함수 (0) | 2022.09.12 |
| [딥러닝] 파이토치(PyTorch)로 모델 구현 실습🎯- MNIST 손글씨 데이터셋 (2) | 2022.09.03 |
| [딥러닝] 로지스틱 회귀(Logistic Regression) 개념부터 실습까지 (0) | 2022.09.03 |
- Total
- Today
- Yesterday
- 프론트엔드 공부
- 파이썬
- react-query
- 자바
- 프로젝트 회고
- 딥러닝
- testing
- 리액트 훅
- 자바스크립트 기초
- 리액트
- HTML
- CSS
- next.js
- rtl
- 프론트엔드 기초
- Python
- TypeScript
- 인프런
- 머신러닝
- JSP
- frontend
- react
- 데이터분석
- 프론트엔드
- 타입스크립트
- styled-components
- 자바스크립트
- jest
- 디프만
- 스타일 컴포넌트 styled-components
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |