
티스토리 뷰

▶파이토치로 딥러닝 모델 구현하기
앞서 공부한 내용을 통합해서 딥러닝 모델 구현 실습을 해보겠습니다.
[머신러닝] ⑭ 딥러닝 선형 회귀(Linear Regression)
▶딥러닝 선형회귀 선형 회귀의 핵심은 학습 데이트와 가장 잘 맞는 직선을 찾는 작업이라고 할 수 있습니다. ▷라이브러리 import 우선 필요한 라이브러리를 import 해주겠습니다. import torch import t
doeunn.tistory.com
[머신러닝] ⑮ 딥러닝 다중선형회귀
▶딥러닝 다중선형회귀 앞서 X와 Y가 하나씩 존재하는 선형회귀에 대해 공부해 보았습니다. 이번에는 X변수가 여러 개인 다중 선형회귀에 대해서 알아보겠습니다. 다중선형회귀는 여러 개의 특
doeunn.tistory.com
[머신러닝] ⑯ 딥러닝 로지스틱 회귀(Logistic Regression) 개념부터 실습까지
▶딥러닝 로지스틱 회귀 우선 로지스틱에 대해 알아보고 코드를 살펴봅시다. ▷선형회귀 vs 로지스틱 회귀 션형 회귀도 로지스틱 회귀 모두 지도학습으로 학습 데이터로부터 x → y의 관계를 설
doeunn.tistory.com
1) 라이브러리 import
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplot as plt
import numpy as np
2) torchvision의 datasets으로 데이터 불러오기
training_data = datasets.MNIST( # MNIST: 손글씨 데이터셋
root='data',
train=True,
download=True,
transform=ToTensor() # 데이터셋 불러와서 바로 텐서로 변환
)
test_data = datasets.MNIST(
root='data',
train=False,
download=True,
transform=ToTensor
)
3) 데이터로더(DataLoader) 생성
데이터로더는 데이터를 좀 더 쉽게 나눌 수 있도록 도와주는 파이토치 및 텐서플로우에서 제공하는 라이브러리입니다.
데이터로더를 통해 배치 학습, 데이터 사용, 병렬 처리 등 간단하게 수행이 가능하게 해줍니다.
batch_size = 64
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)test_dataloader를 통해 shape와 미니배치 하나를 출력해보겠습니다.
이 과정은 확인을 위함입니다.
for X, y in test_dataloader:
print('Shape of X [N, C, H, W]: ', X.shape) # 28x28 사이즈
print('Shape of y: ', y.shape, y.dtype)
print(y)
break # 미니배치 1개만 출력
print(len(test_dataloader))out:

+ google colab에서 GPU 사용하기
구글 코랩에서 GPU를 사용할 수 있습니다.
방법은 다음과 같습니다.

상단 메뉴레어 런타임 클릭 후 하단에 런타임 유형 변경을 클릭합니다.

이후 하드웨어 가속기에서 GPU 옵션을 선택해 줍니다.
다음 코드는 CPU 환경/GPU 환경에 맞게 코드를 실행하기 위해 작성해주었습니다.
# 학습에 사용할 CPU 장치나 GPU 장치를 얻음
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('사용중인 디바이스: {}'.format(device))
4) class 정의해서 모델 생성
class NeuralNetWord(nn.Module):
def __init__(self):
super.__init__()
self.flatten = nn.Flatten() # 행렬로 데이터가 존재할 때 1차원 데이터(일렬로)로 변경해줌
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Dropout(0.2) # 과대적합을 방지하기 위해 20% 데이터는 적용X. shuffle하면서 사용.
nn.Linear(128, 10)
)
def forward(self, x):
x = self.flatten(x) # 행렬이 들어오면 펼쳐짐
logits = self.linear_relu_stack(x)
return logits # 손글씨 숫자가 1부터 10까지 있어서 그에 해당하는 10개의 확률값이 리턴됨방금 정의한 class로 모델을 생성합시다.
model = NeuralNetwork().to(device) # GPU에 모델이 만들어지게 됩니다.
print(model)out:

5) 오차함수(Loss Function), 옵티마이저(Optimizer) 생성
최적화를 할 때 오차 함수의 값이 얼마나 줄어드느냐에 따라 진행되게 됩니다.
이를 위해 오차함수를 정의해줍니다.
loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
6) 모델 학습을 위한 함수 정의
def train(dataloader, model, loss, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
X, y = X.t(device), y.to(device)
# 예측 오류 계산
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad() # 가중치 누적 방지를 위해 에폭 돌 때마다 초기화
loss.backward()
optimizer.step()
if batch%100 == 0
loss, current = loo.item(), batch * len(X)
print(f'loss:{loss:>7f} [{current:>5d}/{size:>5d}]')
7) 모델 학습 - '배치 크기 * 에폭'만큼 가중치 업데이트
epochs = 10
for t in range(epochs):
print(f'Epoch {t+1}\---------------------')
train(train_dataloader, model, loss_fn, optimizer)
print('끝!')out:
...

8) 모델 테스트를 위한 함수 정의
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() # dropout을 작동시킴
test_loss, current = 0, 0
# autograd를 사용하지 않으므로 메모리 사용량을 줄이고 연산 속도를 높임
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = mode(X)
test_loss += loss_fn(pred, y).item()
current += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
current /= size
print(f'Test Error: \n Accuracy: {(100*current):>0.1f}%, Avg loss: {test_loss:>8f} \n')
9) 모델 테스트 - 에폭마다 학습/테스트 반복
epochs = 10
for t in range(epochs):
print(f'Epoch {t+1}\--------------------')
train(train_dataloader, model, loss_fn, optimizer)
test(train_dataloader, model, loss_fn)
print('끝!')out:
...

10) 모델 사용해 보기 - 직접 손글씨 써서 데이터 넣어보기
코드를 작성하기 전에 그림판에서 손글씨를 직접 써서 데이터를 만들어보겠습니다.
추후에 이미지 리사이즈를 해줄 것이지만, 위에서 알아놓았던 사이즈인 28x28얼추 비슷한 크기로 조정하여 손글씨를 써 보도록 하겠습니다.
우선 그림판을 열어 크기를 조정해 줍니다.

이제 자신이 테스트 해보고 싶은 숫자(0~9)를 하나 써 봅시다.
저는 5를 썼습니다.
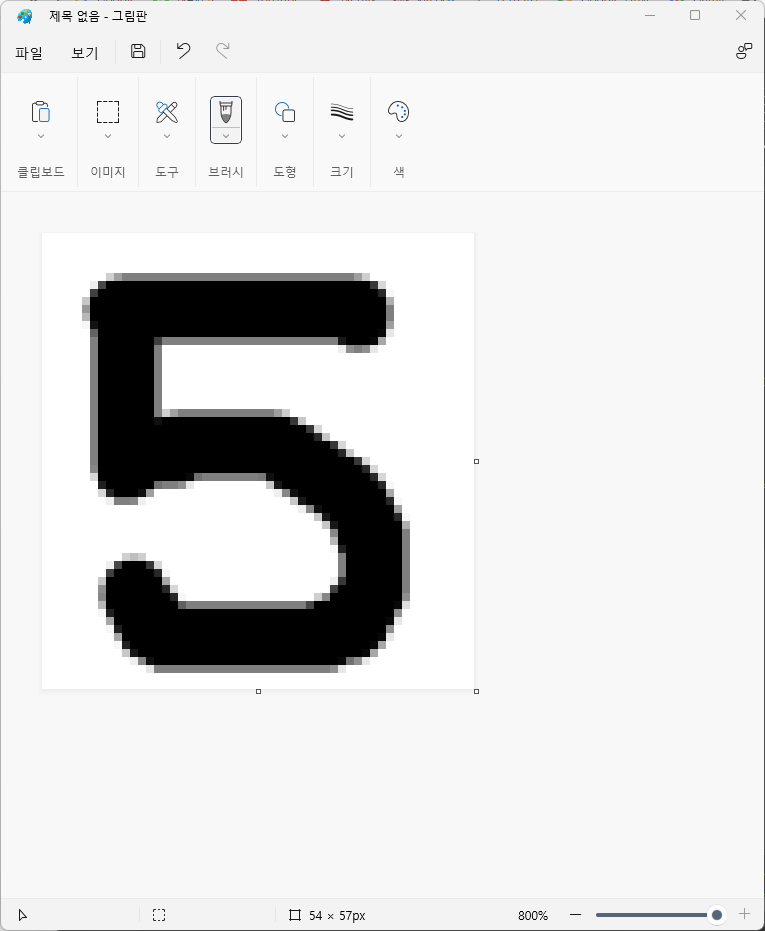
이제 파일을 업로드 해서 테스트 해봅시다.
저는 현재 구글 코랩에서 작업을 하고 있어서 코랩에서 파일을 선택하고 업로드하는 라이브러리를 사용해 보겠습니다.
import os
from PLT import Image
from google.colab import files
uploaded - files.upload()
for fn in uploaded.keys():
print('file:{name}, length:{length}bytes'.format(name=fn, length=len(uploaded[fn])))실행하게 되면 다음과 같이 출력됩니다.

이 상태로 두면 코랩에서 계속 실행중인 것으로 표시되는데, 파일 선택 버튼을 눌러 그림판에서 쓴 손글씨 이미지를 선택해줍니다.

선택해주면 다음과 같이 다시 출력됩니다.

이제 데이터를 정제를 해줘야 합니다.
- 크기를 28x28로 리사이즈
- 이미지를 검정 화면에 하얀색 글씨로 색반전
색반전을 해주는 이유는 학습된 MNIST 데이터셋들이 다음과 같은 형태이기 때문입니다.

cur_dir = os.getcwd() # 현재 작업 디렉토리 경로를 불러옴
img_path = os.path.join(cur_dir, '5.png') # 작업 디렉토리 안에 있는 '5.png'파일 불러옴
cur_img = Image.open(img_path)
cur_img = cur_img.resize((28, 28)) # 리사이즈
image = np.asarray(cur_img) # ndarray 배열로 바꿔줌.
try:
image = np.mean(image, axis=2) # axis=2 : color 채널
except:
pass
image = np.abs(255-image) # 색반전. 검정->흰, 흰->검정
image = Image.astype(np.float32) / 255 # 0~1 사이의 소수. 척도를 맞춰주기 위해
plt.imshow(image, cmap='gray')
plt.show()out:
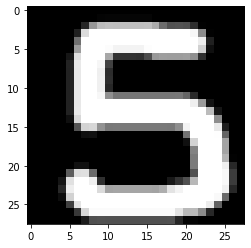
이제 우리가 학습시킨 모델이 위 사진을 5라고 예측하는지 확인해보겠습니다.
image = torch.as_tensor(image).to(device).reshape(1, 1, 28, 28)
# eval() : 모든 레이어가 evaluation mode로 변경. 학습할 때만 필요한 Dropout, Batchnorm들의 기능을 비활성화. 메로리 절약
model.eval()
predict = model(image)
print('model이 예측한 값: {}'.format(predcit.argmax(1).item())) # 가장 확률이 높다고 하는 숫자를 출력out:

11) 모델 저장하기, 불러오기
우리가 실제로 모델을 잘 학습시켜서 어딘가에 넘겨주고
그 모델을 예를 들어 앱이나 웹에 적용하게 될 때 모델을 저장해서 넘겨주어야겠죠?
그때 필요한 모델을 저장하는 방법에 대해 알아보겠습니다.
① 학습된 모델 파라미터 저장
torch.save(model.state_dict(), 'model_weight.pth')
저장된 파라미터를 새로운 모델에 사용하는 방법은 다음과 같습니다.
# 새로운 모델을 생성
model2 = NeuralNetwork().to(device) # 학습전
# 저장된 파라미터 불러오기
model2.load_state_dict(torch.load('model_weights.pth')) # model2에 이전에 학습해둔 파라미터가 적용됨
② 모델 전체를 저장
torch.save(model, 'model.pth')저장된 모델을 새로운 모델에 불러와보겠습니다.
model3 = torch.load('model.pth')
여기까지 파이토치로 딥러닝 모델 구현하는 실습을 해보았습니다 :)
'빅데이터 인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝] Oxford Pets Dataset 실습🎯 (0) | 2022.09.18 |
|---|---|
| [딥러닝] 역전파(Backpropagation) - 경사하강법 & 활성화 함수 (0) | 2022.09.12 |
| [딥러닝] 로지스틱 회귀(Logistic Regression) 개념부터 실습까지 (0) | 2022.09.03 |
| [딥러닝] 다중선형회귀(Multi Linear Regression) (0) | 2022.08.30 |
| [딥러닝] 선형 회귀(Linear Regression) (0) | 2022.08.29 |
- Total
- Today
- Yesterday
- 인프런
- 자바
- react
- JSP
- 딥러닝
- 프론트엔드 기초
- 프론트엔드 공부
- HTML
- 자바스크립트 기초
- CSS
- 리액트
- 머신러닝
- styled-components
- 파이썬
- next.js
- 데이터분석
- Python
- 리액트 훅
- 타입스크립트
- TypeScript
- 스타일 컴포넌트 styled-components
- 프로젝트 회고
- jest
- react-query
- testing
- 자바스크립트
- frontend
- 프론트엔드
- 디프만
- rtl
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |