
티스토리 뷰

지난 글에 이어 pandas 모듈에 대해 알아봅시다 :)

14) row, column 추가 및 삭제
- row의 추가
- dictionary 형태의 데이터를 만들어주고 append() 함수를 사용해서 데이터를 추가
- 반드시 ignore_index = True 옵션을 추가해서 에러가 나지 않음
df.append({'이름':'김사과','그룹':'애플','소속사':'apple','성별':'여자','생년월일':'2000-01-01','키':160,'혈액형':'A','브랜드평판지수':12345678},ignore_index=True)
- column의 추가
df['국적'] = '대한민국'이런 경우에는 '국적' 이라는 새로운 컬럼을 만들어서, 이 칼럼의 모든 데이터를 일괄적으로 '대한민국'으로 입력하게 됩니다.
15) 통계값 다루기
# 모든 데이터 정보 보기
df.info()# 통계값 보기 (정수나 실수 타입 컬럼만 통계)
df.describe()df['키'].min() # 최솟값
df['키'].max() # 최댓값
df['키'].sum() # 합계
df['키'].mean() # 평균
df['키'].std() # 표준편차
df['키'].var() # 분산
df['키'].median() # 중앙값
df['키'].mode() # 최빈값
16) 그룹으로 묶기 - groupby()
- groupby()는 데이터를 그룹으로 묶어 분석할 떄 사용
- 가장 간단한 예를 들어봅시다.
df.groupby('그룹').mean() # 그룹에 따른 통계'그룹' 별로 평균을 구해보자는 말이 되겠습니다.
out::::
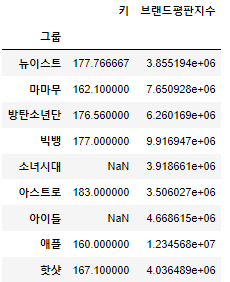
출력된 것을 보게 되면, 그룹별로 키와 브랜드평판지수의 평균이 구해졌음을 확인할 수 있습니다.
- 또 다른 예시를 들어보겠습니다.
# 혈액형별로 그룹을 맺어 키의 평균값을 확인
df.groupby('혈액형')['키'].mean()이 경우에는, '혈액형'별로 키의 평균의 확인하고 싶다는 말이 되겠습니다.
out::::
혈액형
A 171.114286
AB 176.500000
B 183.000000
O 177.875000
Name: 키, dtype: float64
- 그룹을 여러 개
# 혈액형 별로 거기서 성별로 나누어 평균값 확인
df.groupby(['혈액형','성별'])['브랜드평판지수'].mean()혈액형 별로 보고 거기서 또 다시 성별 별로 브랜드평판지수의 평균이 궁금하다는 말이 되겠습니다.
out::::
혈액형 성별
A 남자 7.591755e+06
여자 7.971756e+06
AB 남자 5.687578e+06
B 남자 3.506027e+06
여자 4.668615e+06
O 남자 3.939920e+06
Name: 브랜드평판지수, dtype: float64
17) 결측값 채우기
# 결측값을 채워주는 fillna()
df['키'].fillna(-1) # 결측값을 -1로 저장해줌참고로, 위의 코드는 저장해주지는 않습니다.
물론 df['키'] = ... 하고 저장할 수는 있지만, 함수의 조건을 이용한 방법이 있습니다.
# df2['키'] = df2['키'].fillna(-1)
df2['키'].fillna(-1, inplace=True)
18) 결측값 제거
- 결측값이 있는 행 제거
df.dropna(axis=0) # 결측값가 있는 행 제거
- 결측값이 있는 열 제거
df.dropna(axis=1) # 결측값가 있는 열 제거
- 결측값이 하나라도 있는 경우 삭제
df.dropna(axis=0, how='any') # NaN이 한개라도 있는 경우 삭제
- 모두 NaN인 경우 삭제
df.dropna(axis=0, how='all') # 모두 NaN인 경우 삭제
19) 중복값 제거
df['혈액형'].drop_duplicates()
20) 컬럼 / 로우 제거하기
- 열 통째로 제거하기
df.drop('그룹', axis=1) # '그룹' 열 제거'그룹'행을 제거하고 싶은 거니까 axis=1(열)을 drop 한다고 이해하면 되겠습니다.
- 열 두개를 통째로 한번에 제거하기
df.drop(['그룹','소속사'], axis=1) # 두 개의 행을 제거하고 싶을 때리스트로 묶어서 입력하면 되겠습니다.
- 특정 행 제거
df.drop(15, axis=0) # 15행 제거15행을 제거하고 싶은 거니까 axis=0(행)을 drop 한다고 이해하면 되겠습니다.
21) 데이터프레임 병합
- pd.concat()
- row에 데이터를 합칠 경우에는 pd.concat()을 사용하여 데이터프레임을 list로 합침
- row 기준으로 합칠 경우 sort=False 옵션을 주어 순서가 유지되도록 함
pd.concat([df, df_copy], sort=False)out::::
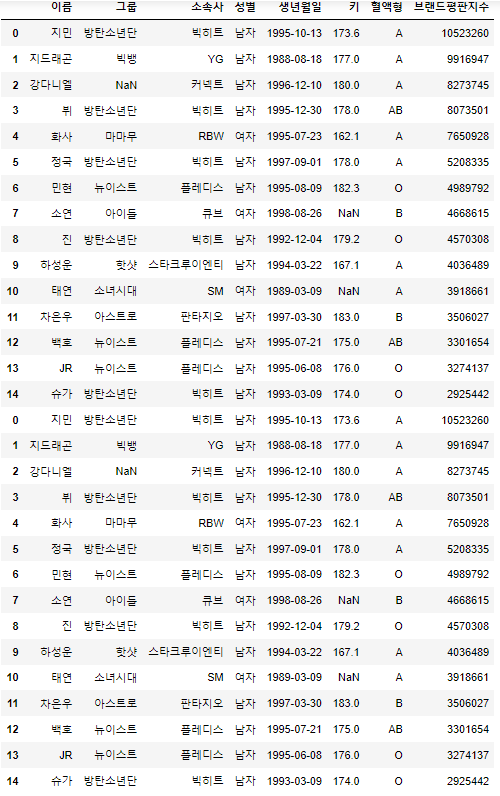
sort=False 옵션을 주었기 때문에 행 기준으로 합쳐졌습니다.
다만, index가 보기 좋진 않아 정리를 해주겠습니다.
df_concat = pd.concat([df, df_copy], sort=False)
df_concat.reset_index(drop=True) # 인덱스를 리셋하고 기존의 인덱스는 dropout::::
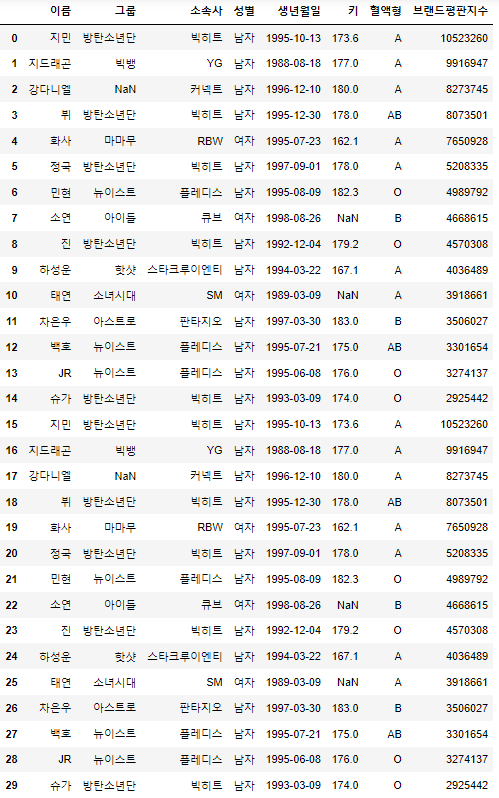
열 기준으로 합치고 싶을 때는 axis=1을 입력하면 되겠습니다.
# column을 기준으로 합칠경우 axis=1 옵션을 설정
pd.concat([df,df2], axis=1)
- pd.merge() - 병합하려는 두 데이터프레임의 인덱스가 맞지 않을 때 사용
pd.merge(df, df_right, on='이름', how='left')
해석을 해보자면, df와 df_right를 병합하려고 하고
on='이름' : 두 데이터프레임 모두 있는 키 값으로 이 키 값을 기준으로 같은 값끼리 병합 (즉, 인덱스가 달라도 값이 같다면 그 값을 찾아 병합)
how='left' : 왼쪽 데이터프레임(=df) 기준으로 병합(df를 두고 df의 키의 값과 같은 값을 찾아 병합)
pd.merge(df, df_right, on='이름', how='inner')how='inner' : 두 데이터프레임에 모두 키 값이 존재하는 경우만 병합
pd.merge(df, df_right, on='이름', how='outer')how='outer' : 두 데이터프레임에 있는 모든 값들을 보여줌
참고로, 키 값은 다르지만 데이터는 같은 경우 병합하고 싶을 때는 다음과 같습니다. (ex.이름&성함, 식당이름&식당명)
(물론, 컬럼명을 바꿔서 위의 방법대로 병합하는 방법도 있지만요...)
pd.merge(df, df_right, left_on='이름', right_on='성함', how='outer')
22) Series의 Type
- Series의 타입 알아보기
df['키'].dtypes
- Series의 데이터 타입 바꾸기
df['키'].astype(int)다만, 해당 Series에 결측값이 있으면 error가 나게 됩니다.
23) 날짜 변환하기
- dtype: datetime 으로 바꾸기- pd.to_datetime()
현재 df['생년월일']의 dtype은 object 입니다. 시간 계산을 편하게 하기 위해 데이터 타입을 datetime으로 변경해주겠습니다.
pd.to_datetime(df['생년월일'])
- 날짜 성분 알아보기
df['생년월일'].dt.dayofweek #dt.datofweek: 요일(0:월요일 ~ 6:일요일)
df['생년월일'].dt.year # dt.year: 연도
df['생년월일'].dt.month # dt.month : 월
df['생년월일'].dt.day # dt.day: 일
df['생년월일'].dt.hour # dt.hour: 시
df['생년월일'].dt.minute # dt.minute: 분
df['생년월일'].dt.second # dt.second: 초
df['생년월일'].dt.weekofyear # dt.weekofyear :일년 중 몇주차
23) apply - 함수를 만들어 적용
- Series나 DataFrame에 좀 더 구체적인 로직을 적용하고 싶을 경우 사용
- apply를 적용하기 위해서는 함수가 먼저 정의되야 함
- 로직 함수를 인자로 넘겨줌
즉, apply 함수를 사용하려면 먼저 로직 함수를 정의해주어야 합니다.
데이터프레임의 '성별' 컬럼에서 '남자':1, '여자':0 으로 바꾸는 함수를 정의해봅시다.
def male_or_female(x):
if x == '남자':
return 1
elif x == '여자':
return 0참고로, 함수식을 lambda식으로 써보겠습니다.
male_or_female = lambda x: 1 if x == '남자' else 0
이제 apply 함수를 이용하겠습니다.
df['성별'].apply(male_or_female) # df['성별']의 모든 데이터가 함수에 적용되게 됨설명을 해보면, df['성별']의 모든 데이터들이 apply를 통해 정의했던 함수에 적용되게 합니다.
24) map - dict를 만들어 적용
위 예시와 똑같이 데이터프레임의 '성별' 컬럼에서 '남자':1, '여자':0 으로 바꿔봅시다.
map_gender = {'남자':1, '여자':0}
df['성별'].map(map_gender)
25) select - select_dtypes()
- 문자만 있는 컬럼만 select
# 문자만 있는 컬럼만 보고 싶을 때
df.select_dtypes(include='object')
# 문자열이 없는 컬럼만 보고 싶을 떄
df.select_dtypes(exclude='object')
26) 원 핫 인코딩(One-Hot-Encoding)
- 원 핫 인코딩은 한개의 요소는 True, 나머지 요소는 False로 만들어주는 기법
pd.get_dummies(df['혈액형_code'])out::::
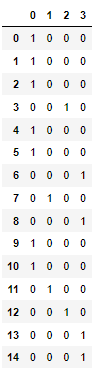

여기까지 pandas 모듈에 대해 알아봤습니다 :)
'빅데이터 인공지능 > 데이터분석' 카테고리의 다른 글
| [데이터분석] ⑥ 쇼핑몰 고객주문 데이터 프로젝트 실습 (0) | 2022.06.30 |
|---|---|
| [데이터분석] ⑤ matplotlib 라이브러리 (0) | 2022.06.28 |
| [데이터분석] ④ 데이터 전처리 활용 및 수행 (0) | 2022.06.27 |
| [데이터분석] ② 기본적인 pandas 모듈(1) (0) | 2022.06.24 |
| [데이터분석] ① 기본적인 numpy 모듈 (0) | 2022.06.23 |
- Total
- Today
- Yesterday
- CSS
- styled-components
- frontend
- 머신러닝
- 자바스크립트 기초
- react-query
- rtl
- 프론트엔드
- TypeScript
- 딥러닝
- react
- 프론트엔드 기초
- 파이썬
- 리액트 훅
- 타입스크립트
- 프로젝트 회고
- next.js
- 프론트엔드 공부
- jest
- 리액트
- HTML
- 디프만
- testing
- 자바
- 스타일 컴포넌트 styled-components
- Python
- JSP
- 자바스크립트
- 인프런
- 데이터분석
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |