
티스토리 뷰

▶스크레이핑(Scraping)
- 크롤링(Crawing) : 인터넷의 데이터를 활용하기 위해 정보들을 분석하고 활용할 수 있게 수집하는 행위
- 크롤링과 같은 개념이지만, 데이터를 추출해서 가공하는 최종 목표
▷크롤링(Crawing)
Web상에 존재하는 contents를 수집하는 작업을 말합니다.
HTML 페이지를 가져와서, HTML/CSS등을 파싱하고, 필요한 데이터만 추출하는 기법이라 할 수 있습니다.
예제를 통해 알아보겠습니다.
1) 영어 교육 사이트
▷링크 : https://basicenglishspeaking.com/daily-english-conversation-topics/
(75 Audio Lessons) Daily English Conversation Practice | Questions and Answers By Topics
Daily English Conversation Practice - Questions and Answers by TopicYou have troubles making real English conversations? You want to improve your Spoken English quickly? You are too busy to join in any English speaking course?Don’t worry. Let us help you
basicenglishspeaking.com

이번 예제에서는 보고 있는 75개의 단어들을 파싱해보겠습니다.
▷라이브러리 불러오기
import requests # 서버에 접속해서 html 문서를 가져오는 역할(요청->응답)
from bs4 import BeautifulSoup # html 문서를 해석하는 역할(파싱)
▷requests 라이브러리를 활용한 HTML 페이지 요청
site = 'https://basicenglishspeaking.com/daily-english-conversation-topics/'
request= requests.get(site) # url에 접속
# print(request) # <Response [200]> : 응답이 왔음을 알려주는 것
html = request.text # html 문서를 가져와서 저장위 코드를 실행하게 되면
request 객체에 HTML 데이터가 저장되게 됩니다. (200 상태코드가 왔기 떄문입니다)
또한, html 객체에는 방금 저장한 request 객체를 이용해서 html 문서를 가져와서 저장합니다.
(이후 BeautifulSoup()의 매개변수로 파싱하고자 하는 문서를 넣기 위해 text로 변환해줍니다)
아래는 print(request) 했을 때의 출력 결과 입니다.
<Response [200]>[200] 은 상태 코드를 의미합니다. 다음 표를 참고해 봅시다.
| 상태 코드 | 상태 설명 |
| 200 | 요청이 성공적으로 처리 |
| 301 | 요청한 자원이 이동 헤더 정보에 이동 위치를 알려줄테니 다시 요청 |
| 304 | 클라이언트가 임시 보관한 응답 결과와 다르지 않다 |
| 400 | 잘못된 요청 |
| 404 | 요청한 자원을 못 찾음 서버 내부에서 오류가 발생 |
| 500 |
▷HTML 페이지 파싱
soup = BeautifulSoup(html) # 매개변수로 파싱할 문서를 넣어서 soup 객체 만들기
▷필요한 데이터가 포함된 구역 파싱

우리가 파싱하고자 하는 부분의 HTML/CSS를 확인 해야합니다.
단축키 중 F12를 누르면 빼곡하게 HTML 코드들을 볼 수 있습니다.
해당 사이트에서 F12를 눌러봅시다. 이 많은 코드들 중에 저 부분을 찾는 방법은 간단합니다.
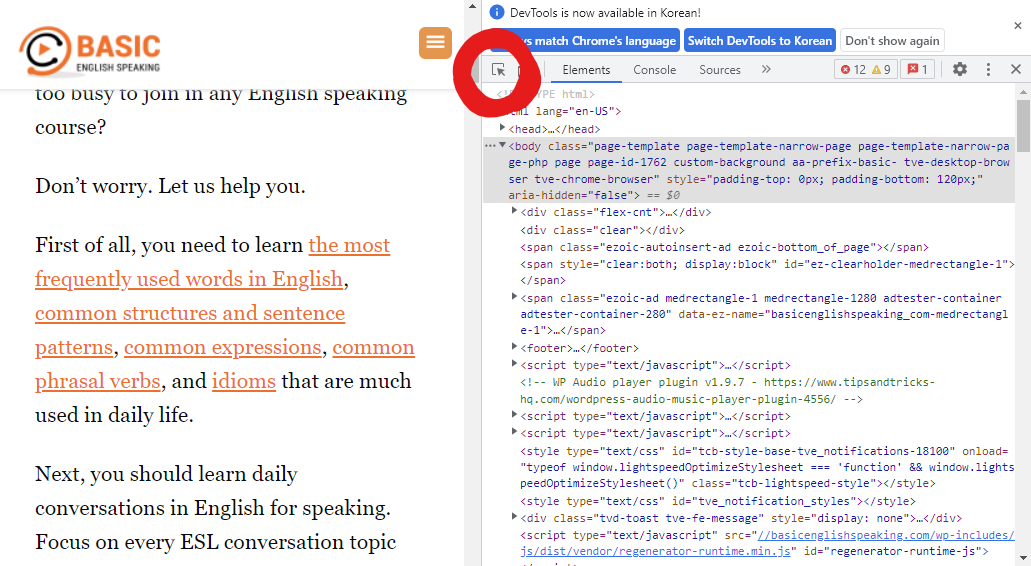
커서 모양의 버튼을 누른 후 화면에 마우스를 가져다 대면 해당하는 부분의 HTML 코드와 매칭해주게 됩니다.
이를 이용해서 우리가 원하는 부분을 찾을 수 있습니다.
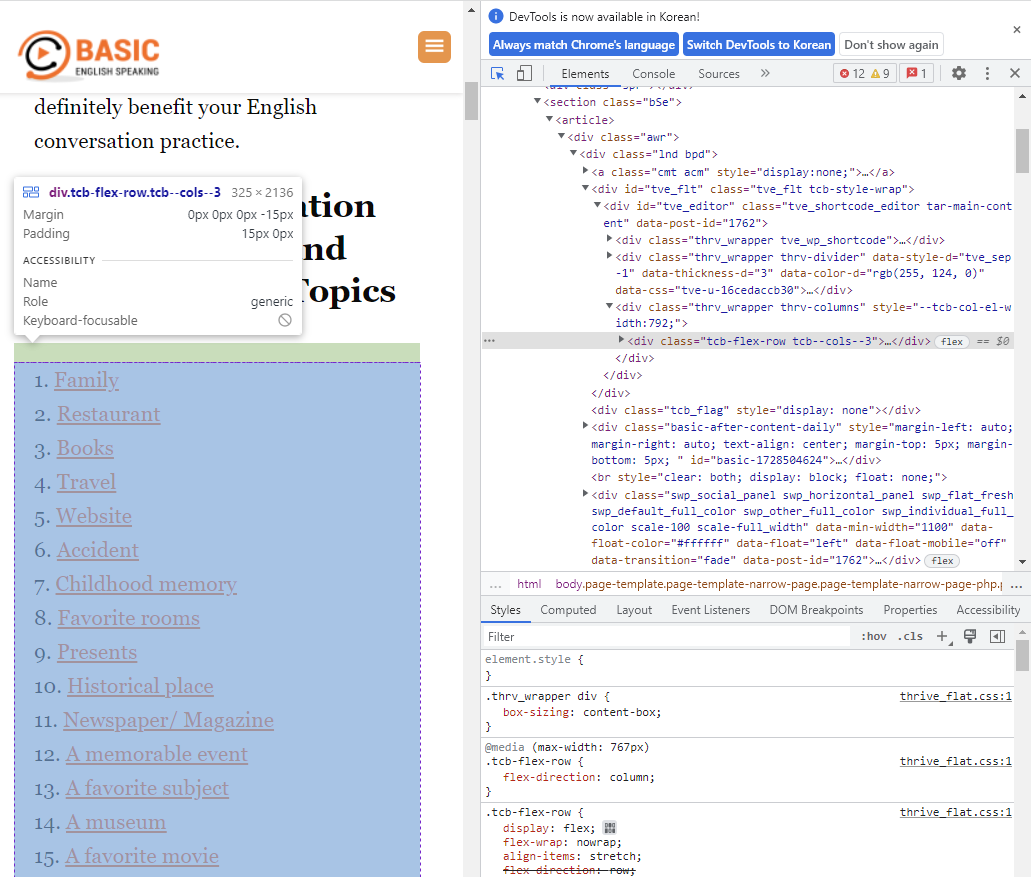
파싱을 할 때는 unique한 값을 이용해서 해당하는 부분을 찾아야 합니다.
위 화면에서 보이는 class="thrv_wrapper thrv-columns"가 되겠는데, 이 값이 unique한지는
ctrl+F 키를 눌러 Find 해봐야 알 수 있습니다.

그러면 이제 이 class 값을 가지고 파싱해봅시다.
divs = soup.findAll('div', {'class':'thrv_wrapper thrv-columns'})
▷데이터 파싱

클릭했을 때 다른 페이지로 넘어가는 태그들을 a 태그라고 합니다.
우리가 파싱하려고 했던 데이터들은 모두 a 태그에 해당합니다.
그러면 우리가 이전에 원하는 데이터가 포함되어 있는 구역을 파싱했습니다.
이제 그 구역에서 a 태그로 되어 있는 데이터만 파싱하면 되겠습니다.
subject = [] # 해당하는 데이터를 저장해둘 리스트
for div in divs:
datas = div.findAll('a') # a 태그만 가져와서 datas에 저장
for data in datas:
subjects.append(data.text) # datas에서 text만 가져와서 subject 리스트에 저장
▷출력해보기
print('총', len(subject), '개의 주제를 찾았습니다.'
for in in range(len(subject)):
print('{0:2d}, {1:s}'.format(i+1, subject[i]))
# {0:2d} : format(A,B)에서 A번째. 즉 0번에 해당하는 부분을 의미함. 2d는 두 자리 숫자를 확보
# {1:s} : format(A,B)에서 B번째. 즉 1번에 해당하는 부분을 의미함. s는 str
2) 벅스 뮤직 차트
▷링크 : https://music.bugs.co.kr/chart
슈퍼사운드 벅스
4천만곡 음악서비스, 슈퍼사운드, 고음질, FLAC, 최신 인기가요, 뮤직PD, 커넥트, 페이코, 추천 플레이리스트, 추천 선곡, 테마 음악
music.bugs.co.kr
위 사이트에서 1위부터 100위까지의 노래 제목과 가수 이름을 파싱해보려고 합니다.
1번 예제와 비슷한 방법으로 파싱 해봅시다.
request = requests.get('https://music.bugs.co.kr/chart')
html = request.text
soup = BeautifulSoup(html)
titles = soup.findAll('p', {'class':'title'})
artists = soup.findAll('p', {'class':'artist'})for i in range(len(titles)):
title = titles[i].text.strip() # text를 가져와서 앞뒤 공백 지우고 저장
artist = artists[i].text.strip.split('\n')[0]
data = '{0:3d}위 {1}-{2}'.format(i+1, artist, title)artist를 저장할 때 title과 유사한 코드로 작성하게 되면, 중간중간 굉장히 큰 공백및 줄바꿈으로 데이터가 변형되게 됩니다.
그래서 위와 같은 코드를 작성함으로써 줄바꿈을 기준으로 split한 후 A/B 이렇게 split했다면 A 데이터를 가져오는 코드를 작성한 것입니다.
3) 멜론 차트 🌟
▷링크 : https://www.melon.com/chart/index.htm
Melon
음악이 필요한 순간, 멜론
www.melon.com
위의 벅스 차트 예제와 동일하게 1위부터 100위까지의 노래 제목과 가수 이름을 파싱해봅시다.
그런데 위와 유사한 코드로 시도하게 되면 파싱이 불가능합니다.
그 이유는 다음과 같습니다.
request = requests.get('https://www.melon.com/chart/index.htm')
print(request)out:::
<Response [406]>즉, 브라우저를 통해 접근하는 것이 아니면 비정상적인 검색으로 인식하여 차단하는 경우입니다.
(일반적으로, 상태 코드가 2XX일 경우 성공적으로 처리되었음을 의미하고, 4XX일 경우 처리되지 않았음으로 이해해도 좋습니다.)
그러면 멜론에서는 파싱이 불가능한걸까요? 아닙니다.
User-Agent 헤더를 통해 접속이 가능합니다. 즉 비정상적인 검색이 아님을 표시해주면 된다는 것입니다.
자신의 User-Agent를 확인하는 방법은 다음 사이트에 접속해보면 쉽게 알 수 있습니다.
UserAgentString.com - unknown version
www.useragentstring.com
자신의 User-Agent를 복사해놓고 다음 코드를 작성해봅시다.
header = {'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
request = requests.get('https://www.melon.com/chart/index.htm', headers=header)
print(request)User-Agent를 url의 헤더로 입력해서 요청하는 것입니다.
out:::
<Response [200]>응답이 잘 왔음을 확인했으니 이제 파싱을 해봅시다.
html = request.text
soup = BeautifulSoup(html)
titles = soup.findAll('div', {'class':'rank01'})
artists = soup.findAll('span', {'class':'checkEllipsis'})출력도 해봅시다.
for i in range(len(titles)):
title = titles[i].text.strip()
artist = artists[i].text.strip().split('\n')[0]
data = '{0:3d}위 {1}-{2}'.format(i+1, artist, title)
print(data)

여기까지 스크레이핑에 대해 알아보았습니다 :)
'빅데이터 인공지능 > 데이터분석' 카테고리의 다른 글
| [데이터분석] ⑨ 형태소 분석 (0) | 2022.07.11 |
|---|---|
| [데이터분석] ⑧ 셀레니움(Selenium) (0) | 2022.07.11 |
| [데이터분석] ⑥ 쇼핑몰 고객주문 데이터 프로젝트 실습 (0) | 2022.06.30 |
| [데이터분석] ⑤ matplotlib 라이브러리 (0) | 2022.06.28 |
| [데이터분석] ④ 데이터 전처리 활용 및 수행 (0) | 2022.06.27 |
- Total
- Today
- Yesterday
- 데이터분석
- 파이썬
- frontend
- Python
- 리액트 훅
- JSP
- TypeScript
- 프론트엔드
- 스타일 컴포넌트 styled-components
- next.js
- HTML
- react
- 프로젝트 회고
- 자바
- jest
- 리액트
- 딥러닝
- 프론트엔드 공부
- react-query
- testing
- styled-components
- 자바스크립트 기초
- rtl
- 자바스크립트
- 타입스크립트
- 디프만
- 머신러닝
- 프론트엔드 기초
- 인프런
- CSS
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |