
티스토리 뷰

▶ RNN을 위한 PyTorch 구현
RNN 학습 과정

t-1 시점의 hidden state와 t 시점의 input vector를 받음 → 학습 → 나온 결과물로 output vector를 도출
RNN 학습 ← U, W, V 이 3가지의 weight를 학습을 하는 것
Text generation
- 이번 글에서 해볼 학습은 Text generation 입니다.
- 예를 들어 'hello'라는 단어가 있다고 했을 때, 모델의 input으로 'h', 'e', 'l', 'l', 'o' 하나하나씩 들어오게 됩니다.
- 이때 input이 'h'일 경우 output은 그 다음 글자 'e'가 됩니다.
- 'e'가 input으로 들어오게 되면 output은 'l'이 되야겠죠?
- 이러한 input과 output을 알고 있다고 했을 때 이와 관련된 파라미터들을 학습하게 되는 구조입니다.

- 이때 각각의 input 들을 원-핫 인코딩을 통해서 임베딩을 하게 되고,
- hidden state들이 업데이트 되게 되는데
- 각각의 hidden layer에서는 이전 단계의 hidden state와 임베딩이 된 input 값을 바탕으로 해서 학습을 하고
- softmax를 통해 최종적으로 결과물을 얻어내는 형태의 과정을 거칩니다.
필요한 모듈 import
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
1. RNN의 간단한 예제
관련된 하이퍼파라미터 정의
- HIDDEN_DIM: hidden state의 차원 크기
- LEARING_RATE: 학습률
- EPOCHS: 에포크
HIDDEN_DIM = 35 # hidden state의 size
LEARNING_RATE = 0.01
EPOCHS = 100
디바이스 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
RNN의 input으로 사용할 string 정의
- 'h', 'e', 'l', 'l', ... 형태로 input으로 들어가게 되고
- 'h'가 input으로 들어갔을 때는 output으로 'e'가 나오는 식으로 학습을 쭉 진행
string = "hello pytorch and data analytics."
input 데이터를 원핫인코딩
- 원핫인코딩을 진행하기 위해 관련된 character들을 정의해줄 필요가 있음
- chars="abcdefghijklmnopqrstuvwxyz .01" : a~z, 공백( ), 마침표(.), 0(start 구분을 위해), 1(end 구분을 위해)
chars = "abcdefghijklmnopqrstuvwxyz .01" # 알파벳, 공백, 콤마, 01(start와 end를 구분하기 위해서)
char_list = [i for i in chars]
n_letters = len(char_list)
n_letters
따라서 위를 통해 원핫인코딩을 통해 임베딩을 하게 되면 그 임베딩의 차원이 30차원이 되겠다 생각할 수 있겠습니다.
이제 임베딩을 위한 함수를 정의해 보겠습니다.
def string_to_onehot(string):
start = np.zeros(shape=n_letters, dtype=int)
end = np.zeros(shape=n_letters, dtype=int)
start[-2] = 1
end[-1] = 1
for i in string: # 미리 정의한 string을 하나씩 돌게 됨
idx = char_list.index(i) # 알파벳을 미리 정의한 characters에서 해당하는 인덱스를 저장
zero = np.zeros(shape=n_letters, dtype=int)
zero[idx] = 1
start = np.vstack([start, zero])
output = np.vstack([start, end])
return output예를 들어 "data"라는 단어를 방금 정의한 함수를 통해 임베딩 해 보겠습니다.
string_to_onehot("data")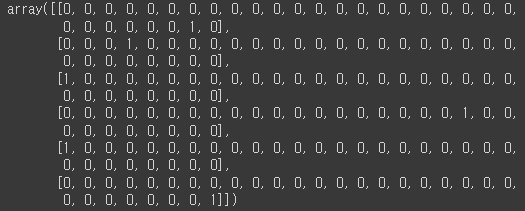
처음 성분과 마지막 성분은 start와 end를 의미하므로 첫번째는 설정한 대로 -2번째 인덱스에 1이 들어가 있는 것을 확인할 수 있고, 마지막 성분에는 -1번째 인덱스에 1이 들어가 있는 것을 확인할 수 있습니다.
이제 단어들의 임베딩을 자세히 보면
먼저 'd'이므로 4번째 알파벳이므로 (정의한 chars에 의해서) 두 번째 줄('d'를 의미하는 성분)을 보면 4번째 성분에 1로 매핑되어 있음을 확인할 수 있습니다.
마찬가지로 'a', 'd', 'a'도 같은 방식으로 임베딩되었습니다.
디코딩해주는 함수도 같이 정의해 두겠습니다.
def onehot_to_string(onehot):
onehot_value = torch.Tensor.numpy(onehot)
return char_list[onehot_value.argmax()]
+ 임베딩(Embedding)
- 임베딩이란 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 혹은 그 과정 전체를 의미
- 임베딩의 가장 간단한 형태는 단어의 빈도를 그대로 벡터로 사용하는 것
- 문서 A, B, C에 단어 i, j, k가 나타나는 빈도를 표로 나타내었을 때
- A의 임베딩은 [0, 1, 1] (i가 0번, j가 1번, k가 1번)
- B의 임베딩은 [3, 0, 0]
- C의 임베딩은 [0, 3, 5]
- 문서 B와 C의 단어 빈도를 살펴봤을 때 매우 유사한 것을 보면
- 문서 B와 문서 C는 비슷한 내용의 문서라고 추정해 볼 수 있음!
- 또한 단어 j와 k는 같이 등장한 것을 보면 단어 j와 k간의 의미 차이가 단어 j와 단어 i 간의 의미 차이보다 작을 것이라고 추정도 가능!
- 문서 A, B, C에 단어 i, j, k가 나타나는 빈도를 표로 나타내었을 때
- 이처럼 임베딩이란 단어나 문장, 문서를 벡터로 변환시킨 값이나 그 과정을 말하며
- 이렇게 변환시킨 벡터 값에 의미와 정보를 손실없이 잘 담아낼 수록 좋은 임베딩이라 할 수 이쏙,
- 임베딩의 방법은 여러가지가 존재
- 대표적인 임베딩 방식: Word2Vec
모델 class 정의
- 모델을 객체를 만들 때 input_size, hidden_size, output_size를 요구하기 위해 __init__ 메소드의 매개변수에 추가
- 필요한 layer #1~3
- RNN 구조를 생각했을 떄 학습을 해야 할 weigh가 어느 부분에 있는지 생각해 보면 총 3가지의 weight 정의 필요
- input → hidden : nn.Linear(input_size, hidden_size) : input을 받아서 hidden으로 학습을 시켜주는 layer
- hidden → hidden
- hidden → output
- RNN 구조를 생각했을 떄 학습을 해야 할 weigh가 어느 부분에 있는지 생각해 보면 총 3가지의 weight 정의 필요
- 필요한 layer #4
- activation : nn.Tanh()
- forward
- 입력으로 받은 (현 시점의) input, (이전 시점의) hidden에 대해서
- 정의한 layer를 각각 통과시켜서 더한 값에 activation function을 적용하면 현 시점의 hidden state 완성
- 입력으로 받은 (현 시점의) input, (이전 시점의) hidden에 대해서
- init_hidden
- hidden vector를 초기화 시켜주는 함수
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.input2hidden = nn.Linear(input_size, hidden_size)
self.hidden2hidden = nn.Linear(hidden_size, hidden_size)
self.hidden2output = nn.Linear(hidden_size, output_size)
self.act_fn = nn.Tanh()
def forward(self, input, hidden):
hidden = self.act_fn(self.input2hidden(input) + self.hidden2hidden(hidden))
output = self.hidden2output(hidden)
return hidden, output
def init_hidden(self):
return torch.zeros(1, self.hidden_size)만든 RNN 클래스를 인스턴스화 시켜주겠습니다.
rnn = RNN(n_letters, HIDDEN_DIM, n_letters).to(device)rnn이 지금 어떻게 구성되어 있는지 간단히 출력해 보겠습니다.
print(rnn)
loss function, optimizer 정의
loss_func = nn.MSELoss().to(device)
optimizer_rnn = torch.optim.Adam(rnn.parameters(), lr=LEARNING_RATE)
학습 진행
- 위에서 정의한 원핫인코딩을 이용한 임베딩 함수를 통해 string을 임베딩
- input_ : 특정한 하나의 character가 들어가서
- output_ : 그 다음의 character가 나오도록
- forward 메소드를 통해 나오는 결과값을 각각 output과 hidden에 저장
- loss: output(학습을 통해 나온 예측값)과 target(정답)이 얼마나 차이가 나는지를 loss로 계산
one_hot = torch.from_numpy(string_to_onehot(string)).type_as(torch.FloatTensor())
for i in range(EPOCHS):
optimizer_rnn.zero_grad()
hidden = rnn.init_hidden()
total_loss = 0
for j in range(one_hot.size()[0]-1):
input_ = one_hot[j:j+1, :].to(device)
target = one_hot[j+1].to(device)
output, hidden = rnn.forward(input_, hidden)
loss = loss_func(output.view(-1), target.view(-1))
total_loss += loss
total_loss.backward()
optimizer_rnn.step()
if i % 50 == 0:
print(total_loss)
start token만 넣어서 확인해 보기
- 위에서 딱 한문장만 학습을 시켜놓았으므로
- 시작 토큰 한 줄을 넣게 되면 학습시켜놓았던 그 문장이 잘 나오는지를 확인
- 학습이 잘 되었다면 거의 비슷하게 문장이 나오게 됨
- start_tkn = torch.zeros(1, n_letters), start_tkn[:, -2] = 1
- 위에서 임베딩할 때 start를 구분하기 위해서 -2번째에 1을 넣었던 것처럼
- 시작 토큰을 생성
- 이걸 우리가 학습시킨 RNN 모델의 input에 넣을 예정
start_tkn = torch.zeros(1, n_letters)
start_tkn[:, -2] = 1
with torch.no_grad():
hidden = rnn.init_hidden()
input_ = start_tkn.to(device)
output_string = ""
for i in range(len(string)):
output, hidden = rnn.forward(input_, hidden)
output_string += onehot_to_string(output.data)
input_ = output
print(output_string)
100% 똑같지는 않지만 한 80% 정도 유사한 문장이 도출되었다고 볼 수 있었습니다.
2. RNN with Embedding
학습 과정

Text generation
- 이번에는 tinyshakespeare dataset을 바탕으로 학습 진행할 예정
- 인코딩 방식
- Word2Vec 방식 사용
- 유사한 character끼리는 유사한 임베딩 스코어를 가지도록 하는 효과 적용 가능
- 원핫인코딩은 그 효과를 주지 못함
- Word2Vec 방식 사용
Embedding ( Word2Vec - CBoW )
- input에 대한 word를 원핫인코딩 형태로 받게 됨
- Word2Vec에는 2가지 학습 방법 존재, 그 중 하나가 CBoW
- CBoW
- cat, sat, on 형태 (cat과 on 사이에 sat이 있는 것)
- 중심 단어를 예측하는 형태로 학습 진행
- 임베딩 하면서 dimension 축소됨 (의미없는 차원은 축소)
- cat, sat, on 형태 (cat과 on 사이에 sat이 있는 것)
- CBoW

tinyshakespeare dataset 다운로드
!wget https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/tinyshakespeare/input.txt -P ./data이제 이 텍스트를 좀 쉽게 읽기 위한 패키지를 install 해줍니다.
!pip install unidecode
필요한 모듈 import
import re
import unidecode
import random
import string
import time, math
import torch
import torch.nn as nn
import torch.nn.functional as F
사용할 파라미터 미리 정의
- CHUNK_LEN: 불러온 데이터셋에서 전체 characters 중 일부만 랜덤하게 추출해서 학습을 진행하기 위해 지정
- NUM_LAYERS: 1개의 layer ( 한층의 hidden layer )
- EMBEDDING: 임베딩 했을 때의 차원을 지정
EPOCHS = 1000
HIDDEN_DIM = 100
BATCH_SIZE = 1
CHUNK_LEN = 250
NUM_LAYERS = 1
EMBEDDING = 70
LEARNING_RATE = 0.004
string 모듈의 printable 메소드를 사용하여 임베딩에 활용할 characters도 정의해 주겠습니다.
characters = string.printable
n_characters = len(characters)
characters
앞서 import한 dataset 모듈을 활용하여 text_file도 정의해 주겠습니다.
text_file = unidecode.unidecode(open('./data/input.txt').read())
len_text_file = len(text_file)
len_text_file
text_file에 100만 character가 넘는 내용들이 포함되어 있는 것을 알 수 있습니다.
일부 character만 랜덤하게 추출 작업
- 100만 개가 넘는 character를 모두 활용할 수 없기 때문에
(개인적인 하드웨어적인 문제..) - 앞서 지정한 CHUNK_LEN에 의해 랜덤하게 250개의 characters가 추출
def random_chunk():
start_index = random.randint(0, len_text_file - CHUNK_LEN)
end_index = start_index + CHUNK_LEN + 1
return text_file[start_index : end_index]
print(random_chunk())
chacater를 tensor로 바꾸는 함수 정의
- 입력한 string의 character를 하나씩 돌면서 그 char가 정의한 characters(모든 characters를 모아둔 문자열)에서의
- 인덱스로 tensor를 만들어 주게 됨
def character_to_tensor(string):
tensor = torch.zeros(len(string)).long()
for char in range(len(string)):
tensor[char] = characters.index(string[char])
return tensor테스트로 하나 출력해 봅시다.
print(character_to_tensor('ABCde'))
이러한 tensor를 통해 임베딩을 진행할 것입니다.
학습 데이터셋 생성(input vector와 output vector로 구성된)
def random_training_set():
chunk = random_chunk()
input = character_to_tensor(chunk[:-1])
target = chracter_to_tensor(chunk[1:])
return input, targetrandom_training_set()
출력된 결과를 잘 보게 되면 13을 input으로 넣었을 때 output으로 14가 나오게 되고
14를 input으로 넣었을 때는 outut으로 10이 나오게 되고, ...
앞서 hello에서 input으로 'h'를 넣게 되면 hello에서 그 다음 character인 'e'가 나오게 끔 학습을 시킨 것과
동일한 내용이 되겠습니다.
모델 class 정의
- 인코딩과 디코딩이 포함된 RNN 모델
- nn.Embedding(input_size, embedding_size) : 모듈에 포함되어 있는 임베딩 메소드
- input을 받아서 몇 차원으로 임베딩 시킬건지 입력
- nn.RNN(input_size, hidden_size, num_layers)
- 앞서서는 RNN을 직접 정의했지만, 여기서는 nn모듈의 RNN을 활용
- input_size = self.embedding_size: 임베딩 vector를 input으로 받게 되므로
- nn.decoder
- output을 도출하는 부분
- forward
- encoder layer에 넣을 때 input을 flatten해서 넣어야 함!
- decoder layer에 넣을 때도 output을 flatten해서 넣어야 함!
- nn.Embedding(input_size, embedding_size) : 모듈에 포함되어 있는 임베딩 메소드
class EN_RNN_DE(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, output_size, num_layers):
super(EN_RNN_DE, self).__init__()
self.input_size = input_size
self.embedding_size = embedding_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
# 임베딩 하는 부분
self.encoder = nn.Embedding(self.input_size, self.embedding_size)
self.rnn = nn.RNN(self.embedding_size, self.hidden_size, self.num_layers)
self.decoder = nn.Linear(self.hidden, self.output_size)
def forward(self, input, hidden):
en_output = self.encoder(input.view(1,-1))
output, hidden = self.rnn(en_output, hidden)
de_output = self.decoder(output.view(1, -1))
return de_output, hidden
def init_hidden(self):
hidden = torch.zeros(self.num_layers, BATCH_SIZE, self.hidden_size)
return hidden모델 class를 다 정의해 주었으니 이제 모델을 인스턴스화 시켜놓겠습니다.
model = EN_RNN_DE(n_characters, EMBEDDING, HIDDEN_DIM, n_chacaters, NUM_LAYERS).to(device)모델의 흐름이 어떻게 진행되는지를 보기 위해 모델에 character 하나를 넣어보겠습니다.
inp = character_to_tensor("A")
print(inp.size())
hidden = model.init_hidden()
print(hidden.size())
out,hidden = model(inp,hidden)
print(hidden.size())
print(out.size())
모델이 어떻게 layers가 쌓여있는지도 확인해 봅시다.
print(model)
loss function과 optimizer 정의
loss_func = nn.CrossEntropyLoss()
optimizer_model = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
학습 진행
for i in ranage(EPOCHS):
input, target, ramdom_training_set()
input = input.to(device)
target = target.to(device)
hidden = model.init_hidden()
loss = torch.tensor([0]).type(torch.FloatTensor)
optimizer_model.zero_grad()
for j in range(CHUNK_LEN=1):
x = input[j]
y_ = target[j].unsqueeze(0).type(torch.LongTensor)
y, hidden = mode(x, hidden)
loss += loss_func(y, y_)
loss.backward()
optimizer_model.step()
if i % 100 == 0:
print(loss/CHUNK_LEN)
loss가 지속해서 감소하는 것을 확인할 수 있었습니다.
결과적으로 text generation이 잘 되었는지 확인!
- 'b'라는 character를 넣었을 때 어떻게 output이 나오게 되는지를 확인
start_string = "b"
input = character_to_tensor(start_string)
hidden = model.init_hidden()
print(start_string, end="")
for i in range(300):
output, hidden = model(input, hidden)
output_dist = output.data.view(-1).div(0.8).exp()
top_i = torch.multinomial(output_dist, 1)[0]
predicted_char = characters[top_i]
print(predicted_char, end="")
input = character_to_tensor(predicted_char)
위와 같은 text가 generation 된 것을 확인할 수 있었습니다.
3. LSTM with Embedding
모델 class 정의
class EN_LSTM_DE(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, output_size, num_layers):
super(EN_LSTM_DE, self).__init__()
self.input_size = input_size
self.embedding_size = embedding_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
# 임베딩 하는 부분
self.encoder = nn.Embedding(self.input_size, self.embedding_size)
self.lstm = nn.LSTM(self.embedding_size, self.hidden_size, self.num_layers)
self.decoder = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, cell):
en_output = self.encoder(input.view(1, -1))
output, {hidden, cell} = self.lstm(en_output, {hidden, cell})
de_output = self.decoder(output.view(1, -1))
return de_output, hidden, cell
def init_hidden(self):
hidden = torch.zeros(self.num_layers, BATCH_SIZE, self.hidden_size)
cell = torch.zeros(self.num_layers, BATCH_SIZE, self.hidden_size)
return hidden, cell모델 class를 정의했으니 모델을 인스턴스화 시켜줍니다.
model_LSTM = EN_LSTM_DE(n_characters, EMBEDDING, HIDDEN_DIM, n_characters, NUM_LAYERS).to(device)모델이 어떤 식으로 layer를 구성하고 있는지도 출력해 봅시다.
print(model_LSTM)
loss function과 optimizer 정의
loss_func = nn.CrossEntropyLoss()
optimizer_lstm = torch.optim.Adam(model_LSTM.parameters(), lr=LEARNING_RATE)
학습 진행
기존 RNN,
인코딩된 input , hidden state → output, hidden state
LSTM,
인코딩된 input, { hidden state, cell state } → output, { hidden state, cell state }
≫ 초기화 할 때도 hidden과 cell을 같이 초기화 해주어야 함!
for i in range(EPOCHS):
input, target = random_training_set()
input = input.to(device)
target = target.to(device)
hidden, cell = model_LSTM.init_hidden()
loss = torch.tensor([0]).type(torch.FloatTensor)
optimizer_lstm.zero_grad()
for j in range(CHUNK_LEN-1):
x = input[j]
y_ = target[j].unsqueeze(0).type(torch.LongTensor)
y, hidden, cell = model_LSTM(x, hidden, cell)
loss += loss_func(y, y_)
loss.backward()
optimizer_lstm,step()
if i % 100 == 0:
print(loss/CHUNK_LEN)
결과적으로 text generation이 잘 되었는지 확인!
start_string = "b"
input = character_to_tensor(start_string)
hidden, cell = model_LSTM.init_hidden()
print(start_string, end="")
for i in range(300):
output, hidden, cell = model_LSTM(input, hidden, cell)
output_dist = output.data.view(-1).div(0.8).exp()
top_i = torch.multinomial(output_dist, 1)[0]
predicted_char = characters[top_i]
print(predicted_char, end="")
input = character_to_tensor(predicted_char)
위와 같은 형태의 text로 generation된 것을 확인할 수 있었습니다.
+ Gated Recurrent Unit
- LSTM과 다르게, cell state를 활용 X
- 기존 RNN 처럼 hidden state와 input만을 바탕으로 해서 구성
- Gated Recurrent Unit이 각광을 받은 이유는?
- LSTM과는 다르게 cell state를 사용하지는 않지만
- LSTM과 거의 비슷한 성능을 보임
- RNN 모델 class를 구성하는 것과 모두 동일한데
- nn.RNN → nn.GRU 로 바꿔주면 바로 구현 가능

'빅데이터 인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝] 오토인코더(Autoencoder) (0) | 2022.12.04 |
|---|---|
| [딥러닝] 전이학습(Transfer Learning) (0) | 2022.12.03 |
| [딥러닝] RNN(Recurrent Neural Network) (1) | 2022.11.30 |
| [딥러닝] CNN 모델 소개(LeNet, AlexNet, VGG, GoogLeNet, ResNet, DenseNet) (0) | 2022.11.28 |
| [딥러닝] CNN을 위한 PyTorch 구현 (0) | 2022.11.28 |
- Total
- Today
- Yesterday
- testing
- TypeScript
- react-query
- styled-components
- jest
- next.js
- 리액트
- 머신러닝
- 자바
- 딥러닝
- CSS
- 프론트엔드 공부
- rtl
- 자바스크립트
- 프로젝트 회고
- Python
- 파이썬
- JSP
- 프론트엔드
- 인프런
- react
- 타입스크립트
- 디프만
- HTML
- 프론트엔드 기초
- 리액트 훅
- 스타일 컴포넌트 styled-components
- 자바스크립트 기초
- frontend
- 데이터분석
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |