빅데이터 인공지능/딥러닝
[딥러닝] 오토인코더(Autoencoder)
doeunnkimm
2022. 12. 4. 00:56

▶오토인코더(Autoencoder)
이번 글에서는 딥러닝의 임베딩이라고도 말할 수 있는 오토인코더에 대해서 알아보겠습니다 :)
1. 등장 배경
- 지난 번 RNN 구현해보는 글에서
- 임베딩을 통해 차원을 축소해서 학습을 진행했었음 (layer를 하나더 쌓음으로써)
- 차원축소는 비지도 학습 종류 중
그래서 차원축소는 왜 하는건데..?
- 차원의 저주
- input 데이터의 차원이 굉장히 크다고 하면 이 데이터로 학습을 하는 것은 어려움
- 생성 모델
- 차원축소를 함으로써 데이터가 가지고 있는 잠재적인 정보 추출 가능
- 그 잠재적인 정보를 바탕으로 또 다른 형태의 데이터 생성 가능
- 데이터 증강(Data Agmentation)과도 관련 있음
우리의 목표
- 우리는 가능한한 차원을 적게 만들어야 함(적은 차원의 벡터로 만들어야 함)
- 그렇지만, 그 과정에서 정보 loss를 최소화하는 방향으로 차원축소가 진행되어야 함
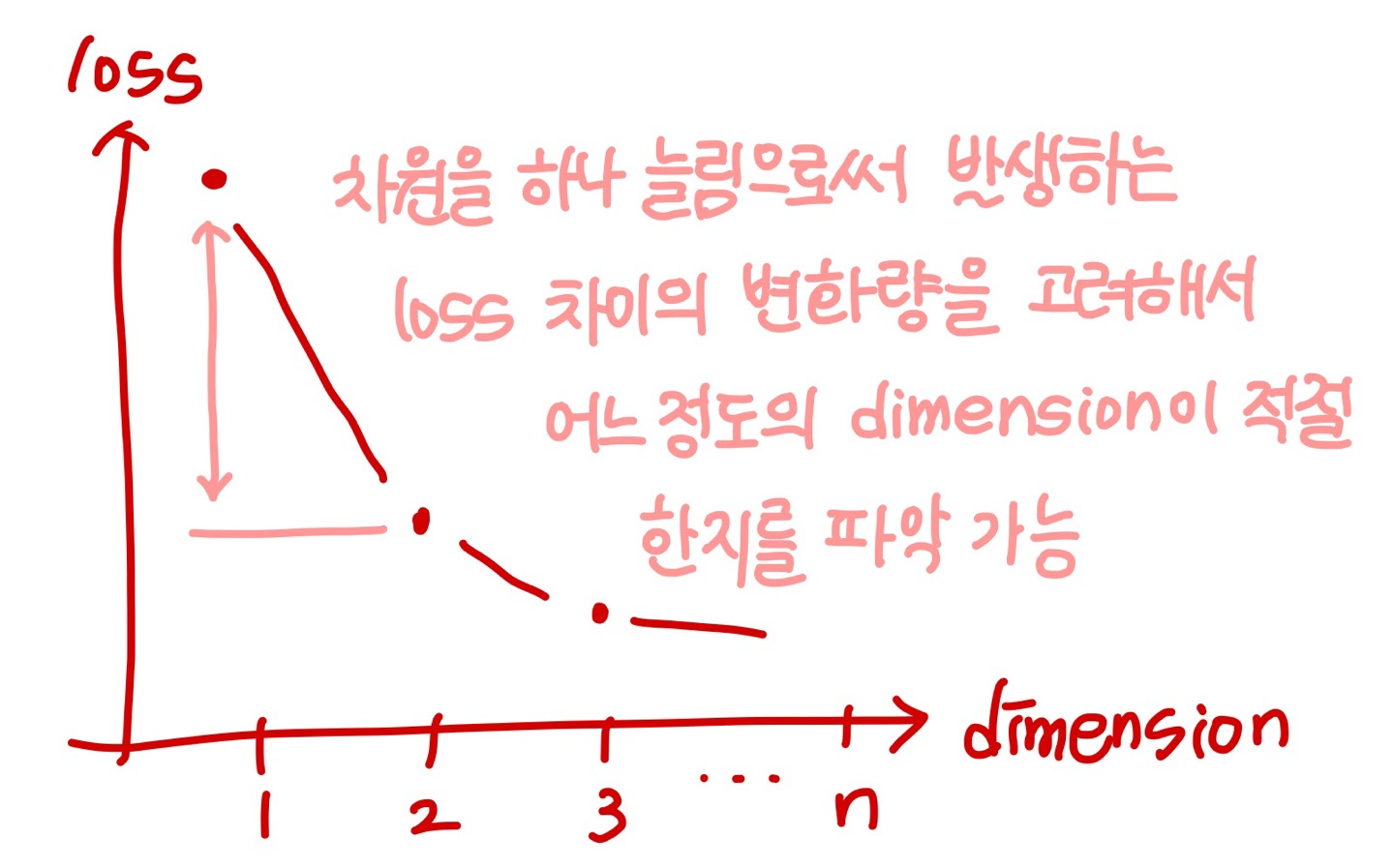
오토인코더는 차원축소의 딥러닝 버전 !
→ 중요한 정보들을 응축하기 위해 사용
2. Autoencoder
Autoencoder의 목적
Autoencoder의 목적
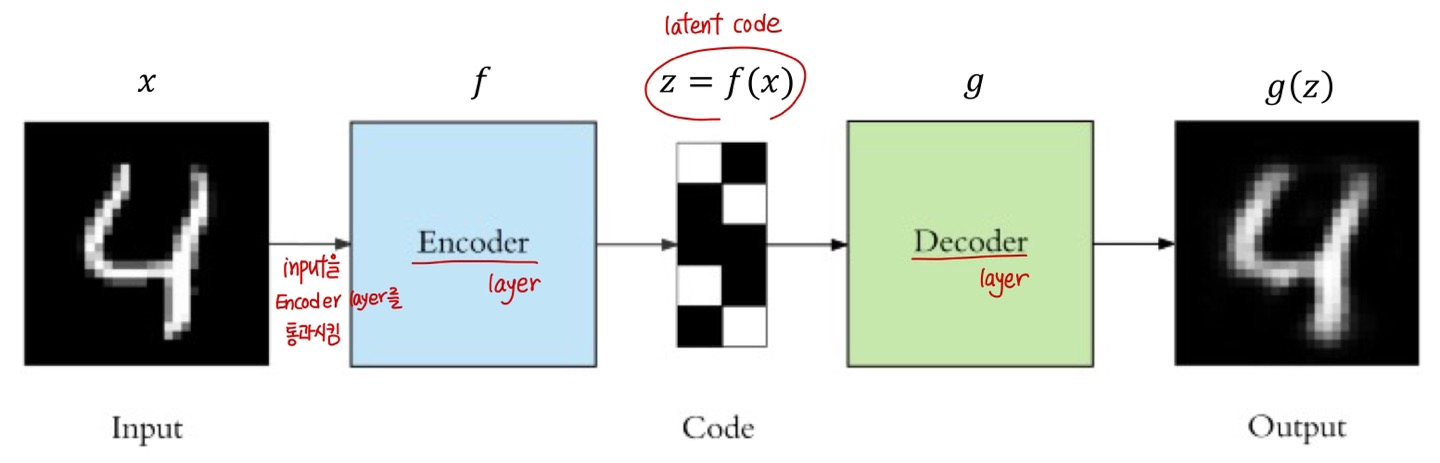
input을 가장 잘 copy해서 input과 거의 동일한 output을 만들어 내도록 네트워크 학습 ❗
Autoencoder의 구성요소 3가지
Autoencoder의 구성요소
① encoder ② (latent) code ③ decoder
- Encoder: \( z = f(x) \)
- latent Code: \( z \)
- Decoder: \( x = g(z) \)
- Autoencoder의 목적: \( g(f(x)) = x \)
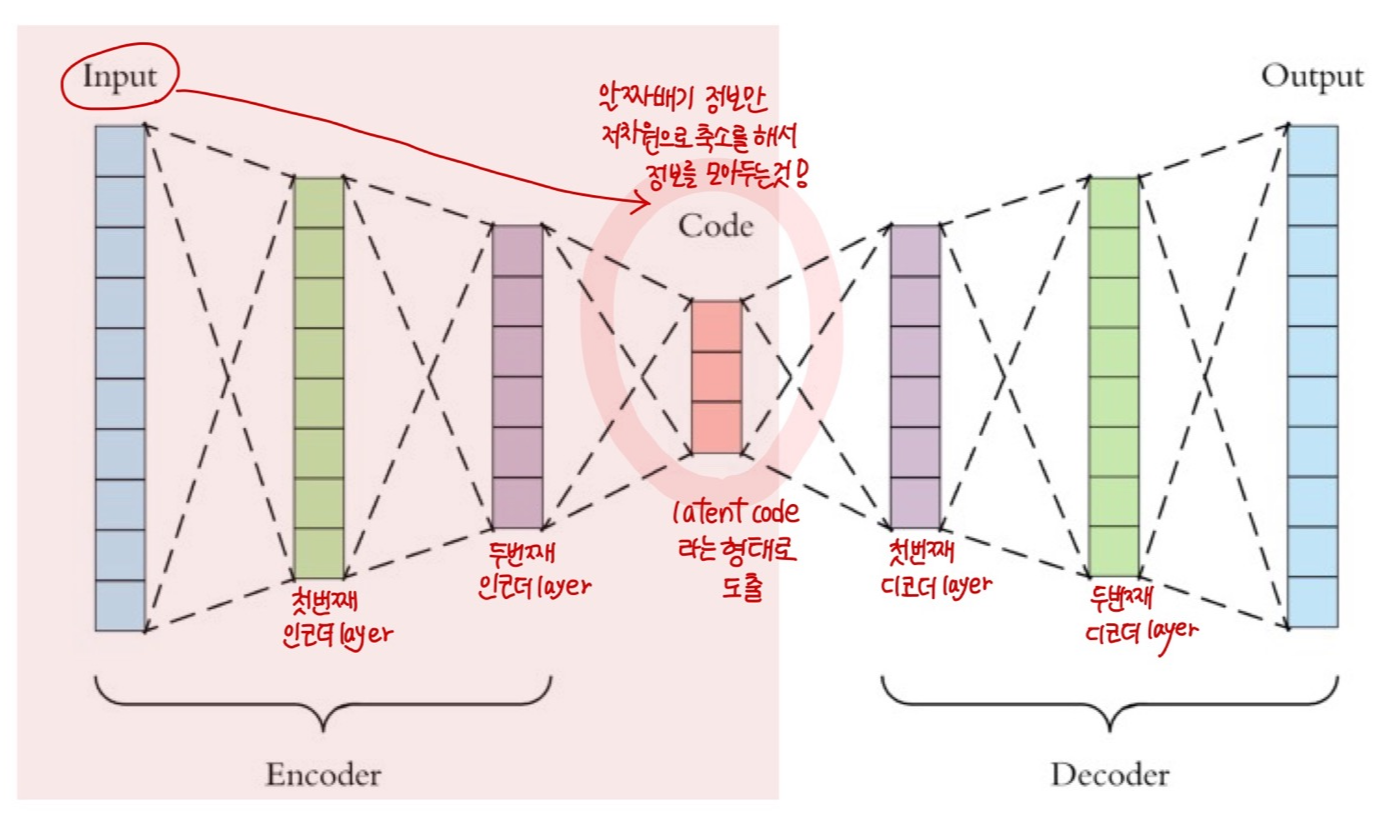
차원축소: Input → latent Code
- Input 데이터로부터 알짜배기 정보만 저차원으로 축소 → latent Code에 중요한 정보를 모아둠!
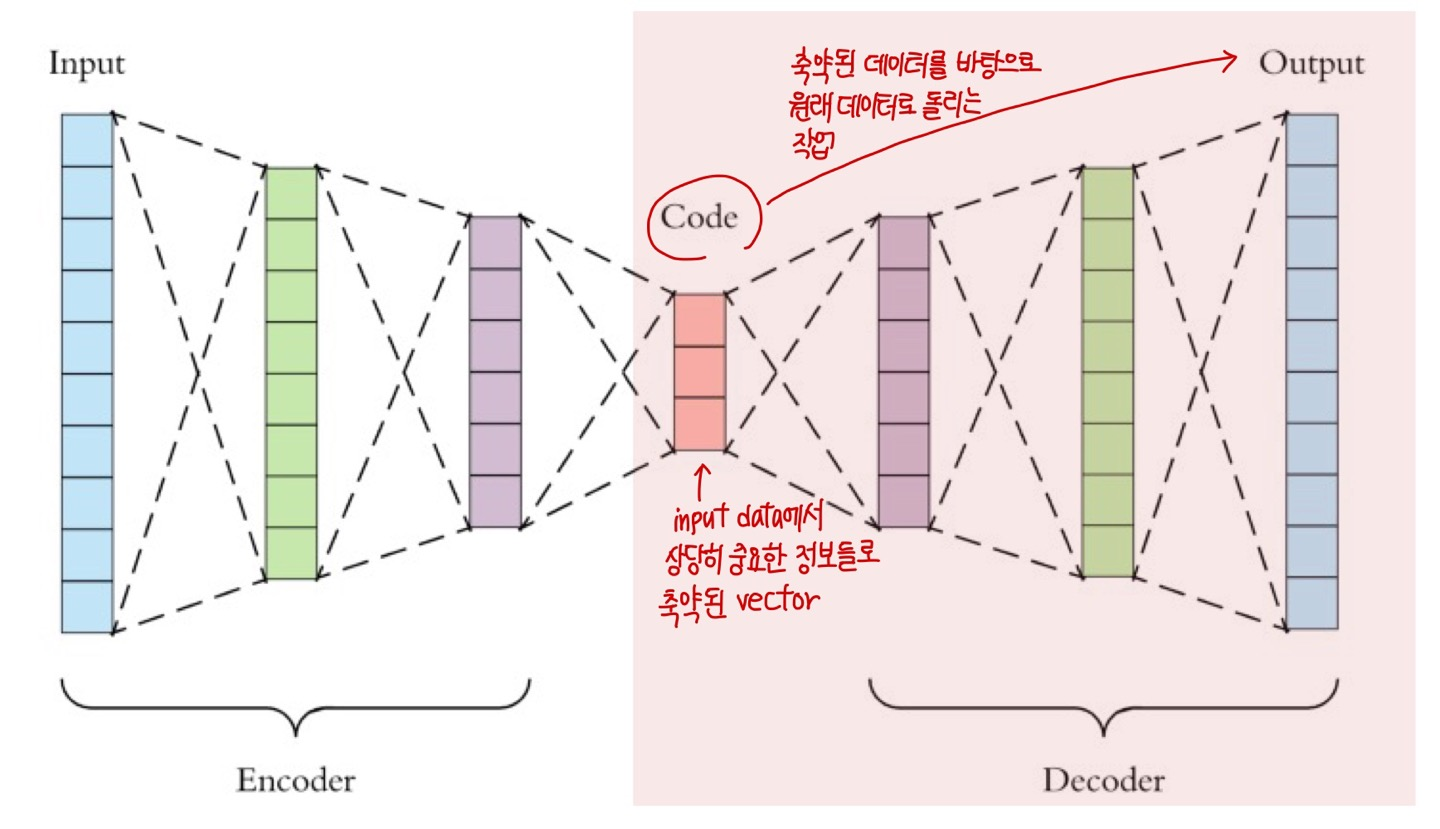
Generative modeling (decoder) : latent Code → output
- latnet Code(축약된 데이터)를 바탕으로 원래 데이터로 돌리는 작업
- input → latent Code 과정에서 차원축소가 잘 되어
- latent Code에 중요한 정보가 잘 담아졌다면
- output 은 input과 거의 동일한 모습이 될 것
latent Code 그거 없으면 안 돼..?
= 고차원 데이터 상에서 그냥 예측 할거야
없는 상황의 문제점을 보기 위해 다음과 같은 상황이 있다고 해봅시다.
만약 첫 번째 이미지와 세 번째 이미지의 중간 정도의 이미지를 예측한다고 했을 때
아래 두 번째 이미지와 같은 위치에 공이 있어야 하겠다고 생각할 수 있습니다.
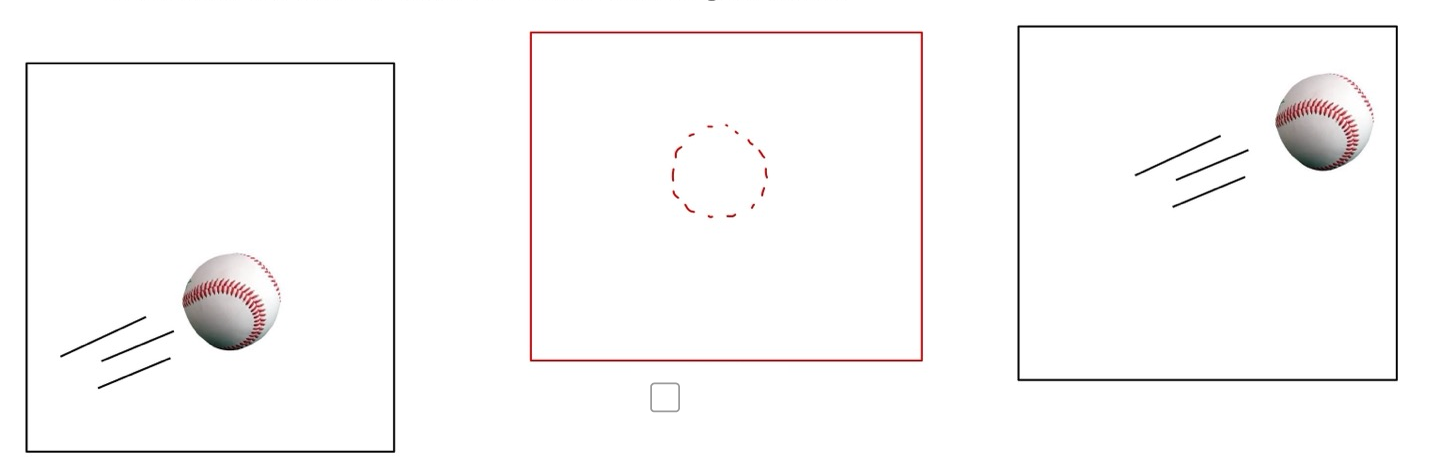
이제 이 이미지들의 위치를 고차원 데이터 상에서 표시해보겠습니다.
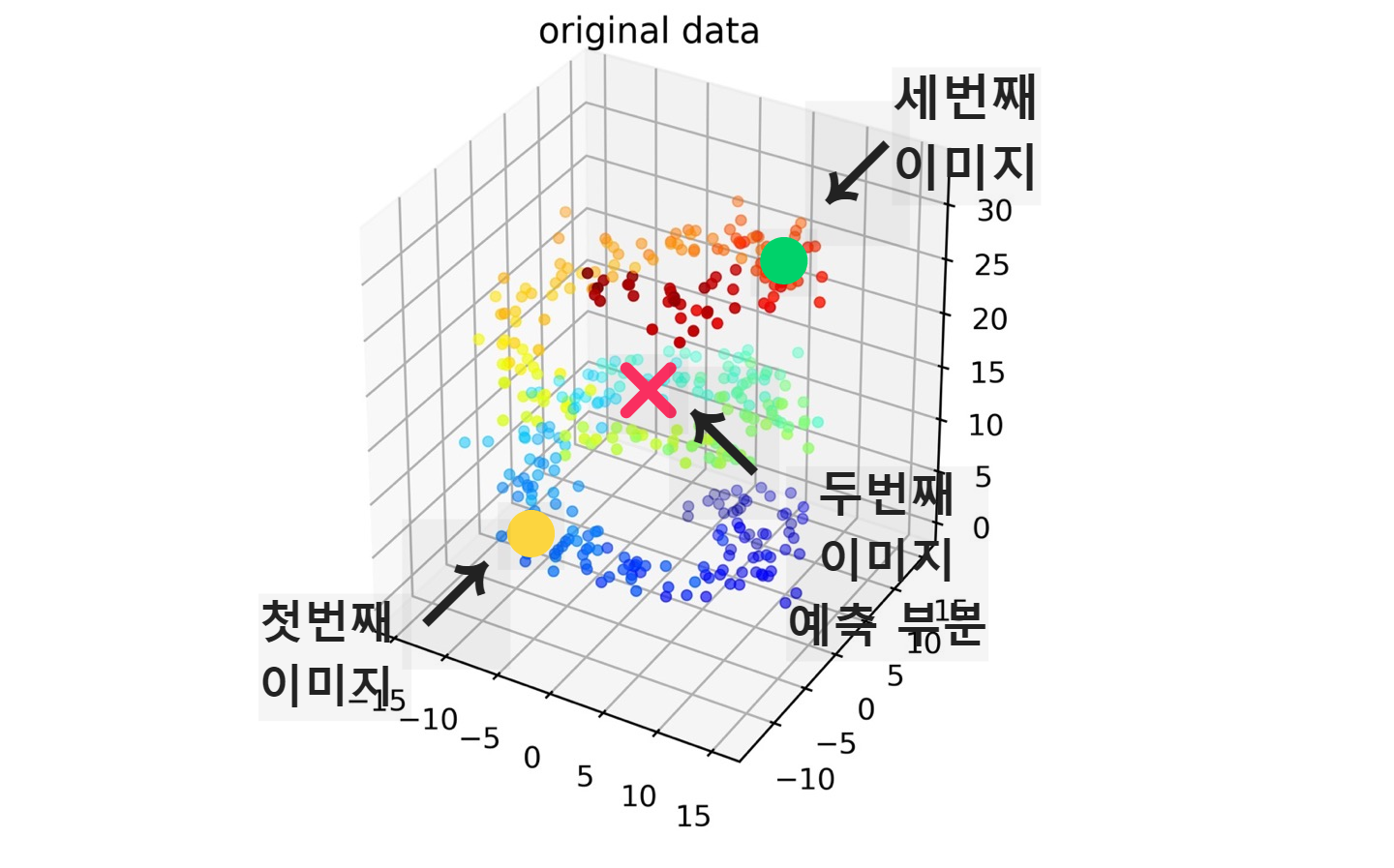
첫 번째 세 번째 이미지의 데이터의 위치와 위와 같다면 두 번째 이미지는 위와 같은 위치에 있을 것이라고 예상할 수 있습니다.
그런데 위 고차원의 데이터를 저차원으로 차원축소를 하면 (flatten) 다음과 같을 것 입니다.
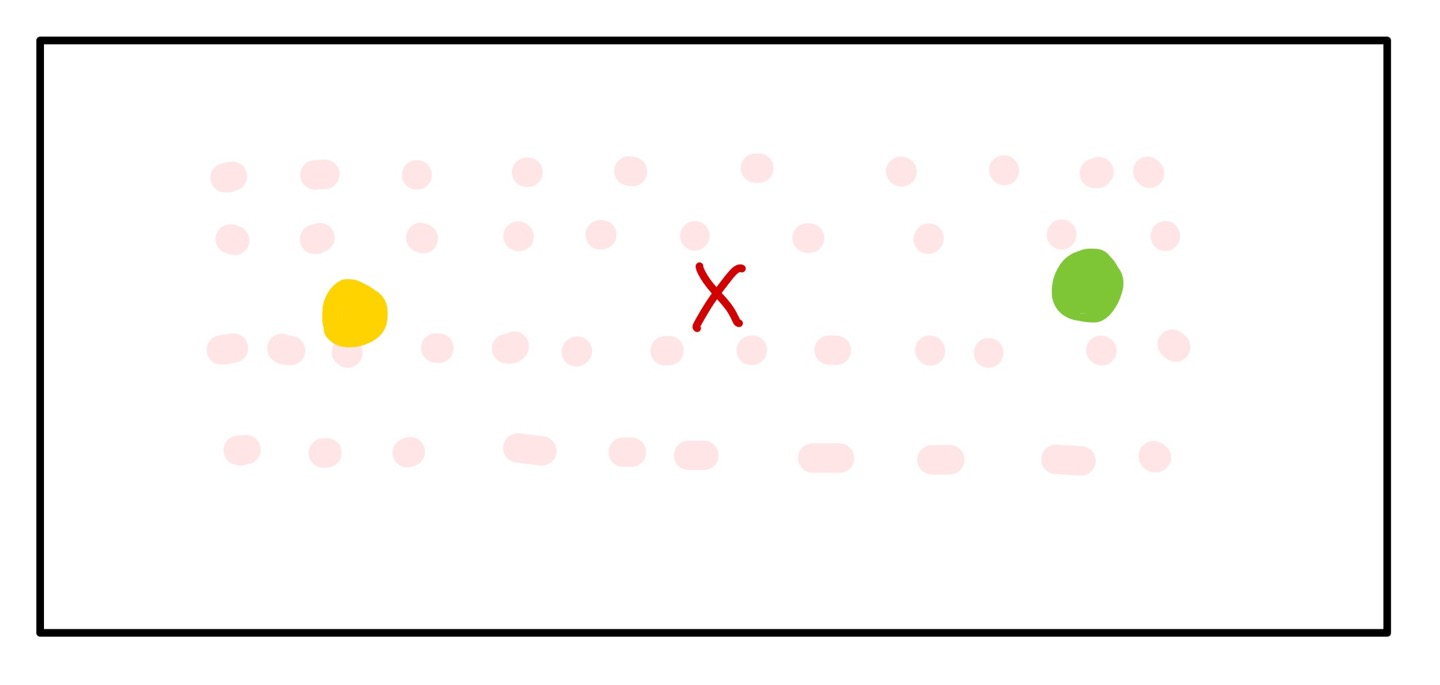
이를 바로 generative modeling을 돌리면 다음과 같이 예상과는 다른 이미지가 도출되게 됩니다.

따라서 중간에 중요한 정보를 가지고 있는 latent code가 필요함을 보여주게 됩니다.
latent Code 예시
latent Code를 바탕으로 generative modeling을 했을 때 유의미한 결과를 얻을 수 있는 것을 확인할 수 있습니다.
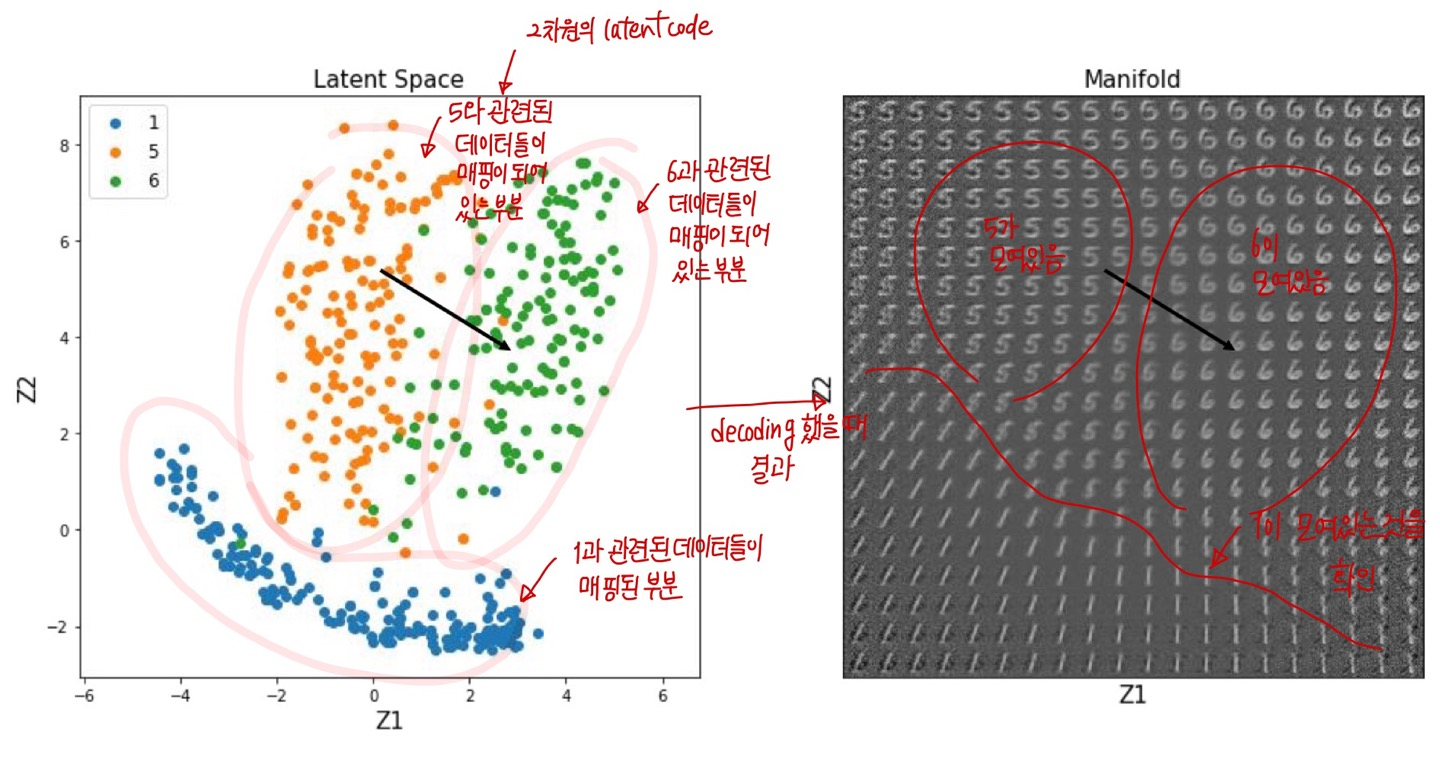
하지만 Autoencoder를 활용을 해서 generative modeling을 할 때 성능이 상당히 좋지 못하다는 한계점이 존재합니다.
그래서 추가적인 방법들(ex. CAE, GAN 등)이 등장하게 되었습니다.
다음에는 이에 대해 알아보도록 하겠습니다 🙂
728x90
LIST